Paper
논문 리뷰 - Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection
| 2020 CVPR에서 발표될 논문이다. (Arxiv | Code) |
Introduction
Object detection 문제는 주로 anchor-based detector에 대한 연구로 진행되었다. anchor-based detector은 미리 세팅해놓은 수 많은 anchor에서 category를 예측하고 coordinates를 조정하는 방식이다. two-stage method와 one-stage method가 존재한다.
하지만 최근에는 FPN과 Focal Loss의 출현으로 인해 anchor-free detector 방식에 대한 연구가 진행되고 있다. anchor-free detector은 anchor 없이 object를 바로 찾을 수 있다. 두 가지 방법이 있는데, 키 포인트를 이용하여 object의 위치를 예측하는 keypoint-based 방법과 object의 중앙을 예측한 후 positive인 경우 object boundary의 거리를 예측하는 center-based 방법이 있다. 이러한 anchor-free detector은 anchor에 관련된 hyperparameter를 사용하지 않고 anchor-based detector와 비슷한 성능을 얻기 때문에, object detection 분야에서 더 잠재력 있다고 여겨진다.
center-based detector은 anchor box 대신에 point를 이용하는 점에서 anchor-based detector와 유사하다. 그래서 one-stage anchor-based detector인 RetinaNet과 center-based anchor-free detector인 FCOS를 비교하였다.
- location 마다 설정해 놓은 anchor(point)의 개수
- positive 또는 negative sample의 정의
- regression starting status
논문에서는 위의 내용을 introduction 부터 설명을 하였지만, 뒤에 어떤 차이가 성능에 큰 영향을 미치는 지에 대한 실험을 포함한 반복적인 내용이 있기 때문에 뒤에 더 자세하게 설명을 하겠다.
논문에서는 anchor-based와 anchor-free 방법의 차이를 실험적으로 설명하며, 성능의 차이는 positive와 negative sample의 정의에 있다고 하였다. 그리고 이에 object 특성에 따라 자동으로 positive, negative sample을 선택하는 Adaptive Training Sample Selection(ATSS)을 제안한다. ATSS로 State-of-the-art AP 50.7% 성능을 얻었으며, 이 방법을 이용하면 많은 anchor를 사용하지 않아도 된다고 한다.
본 리뷰를 정확히 이해하기 위해서는 anchor-based detector와 anchor-free detector에 기본적인 이해가 우선되어야할 것 같다. 밑 reference 부분에 각각 한 가지 모델 논문의 링크를 올려 놓았다.
Difference Analysis of Anchor-based and Anchor-free Detection
대표적인 anchor-based detector RetinaNet과 anchor-free detector FCOS를 비교 실험을 하였다. 각 모델의 논문은 하단에서 볼 수 있다. 위 세 가지 차이 중 두, 세번째 항목에 집중을 한 실험이다. 첫 번째 차이를 없애기 위해 RetinaNet의 location 당 anchor의 개수를 하나로 놓았다. 이로써 FCOS와 비슷한 모델이 완성된다. MS COCO Dataset으로 실험 하였으며 Training Detail과 Inference Detail은 논문을 참고하면 된다.
Inconsistency Removal
우선 anchor box가 하나인 RetinaNet(#A=1) 모델은 32.5% AP 성능을 얻었으며, FCOS 모델은 37.1% AP 성능을 얻었다. 또한 FCOS는 GIoU loss function과 normalizing 기법을 이용하여 37.8% AP 까지 성능을 올릴 수 있다. 하지만 이 비교(37.8% vs 32.5%)는 FCOS에서 사용된 여러 기법들(각 feature pyramid에 사용된 GIoU, GroupNorm, positive sample 제한, centerness branch, 그리고 trainalbe scalar)로 인해 제대로된 비교가 아니다(anchor-free와 anchor-based detector의 본질적인 차이가 아니기 때문에). 따라서 위 기법들을 RetinaNet에도 적용하여 implementation inconsistency를 없앴다.
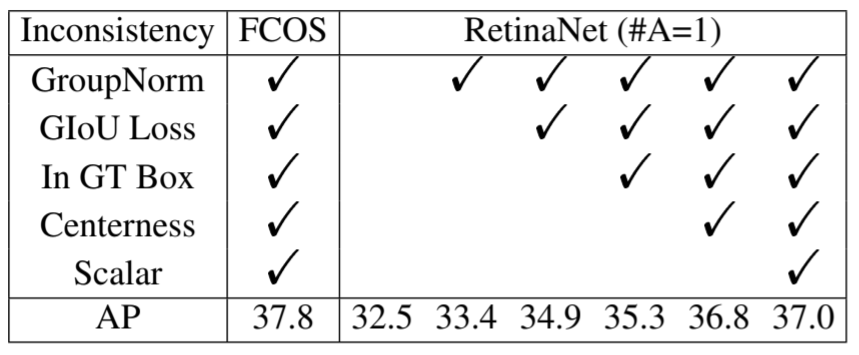
위 표에서 볼 수 있듯이, 이러한 irrelevant difference는 RetinaNet의 성능을 37.0% 까지 높였지만 아직 FCOS에 비해 0.8%의 차이가 존재하였다. 비로서 anchor-based와 anchor-free detector의 근본적인 차이(essential difference)를 파헤칠 수 있다.
FCOS에 적용된 여러 기법들(각 feature pyramid에 사용된 GIoU, GroupNorm, positive sample 제한, centerness branch, 그리고 trainalbe scalar)을 RetinaNet에 적용해서 비교하는게 과연 implementation inconsistency 인지 의문이 들었다.
Essential Difference
이제 RetinaNet(#A=1)과 FCOS에는 두 가지 차이만 존재한다.
- classification sub-task (positive와 negative sample 정의)
- regression sub-task (anchor box 또는 anchor point에서 시작되는 regression)
Classification
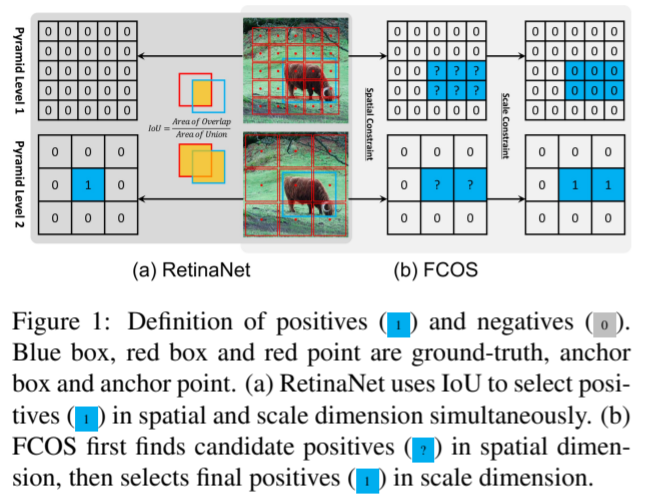
위 Figure 1을 보면 RetinaNet과 FCOS 모델이 positive, negative를 결정하는 대략적인 방법에 대해 알 수 있다. 우선 RetinaNet의 경우 IoU을 이용하여 anchor box를 positive 혹은 negative로 구분한다. IoU가 특정 threshold를 넘지 못하면 학습 단계에서 무시된다. 반면에 FCOS의 경우 spatial constraint, scale constraint를 이용하여 anchor point를 구분한다. ground truth box 안에 있는 anchor point를 positive sample의 후보로 생각을한 후, 미리 정의된 scale range를 통해 최종 positive sample을 결정한다. 이때 선택되지 않은 anchor point는 negative sample 이다.
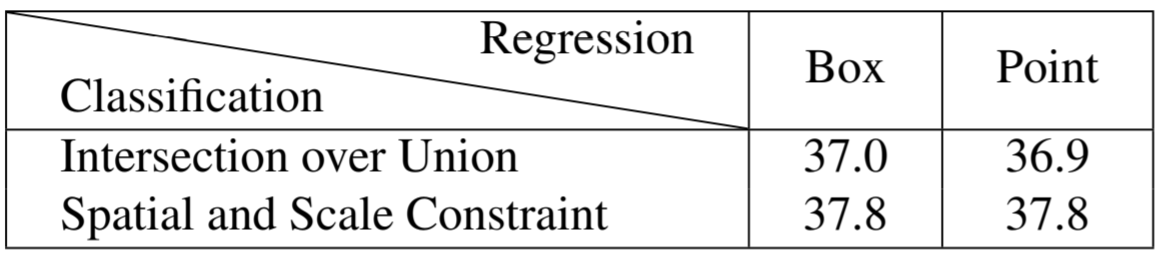
FCOS는 spatial로 후보를 정하고, scale로 선택을 하는 반면 RetinaNet은 IoU를 통해 spatial, scale을 한번에 고려한다. 이 차이는 성능으로 이어진다. 위 표를 보면 RetinaNet(#A=1) (첫 번째 column)에서 IoU 대신 spatial, scale constraint 방식을 사용하니 성능 향상 되는 것을 볼 수 있다. 반대로 FCOS에 IoU 기법을 적용하면 성능이 떨어지는 것을 알 수 있다. 이 부분이 anchor-based와 anchor-free의 본질적인 차이 중 하나이다.
“위 부분이 어떻게 두 방식(anchor-based vs anchor-free)의 차이일까? anchor을 사용하든(anchor-based) 다른 방식(anchor-free)을 사용하든 spatial, scale constraint 기법 유무의 차이가 아닐까?” 라고 생각이 들 수 있다. 하지만 multiple anchor에 spatial, scale constraint 기법을 사용하는 것은 single anchor에 spatial, scale constraint을 사용하는 것과 다름이 없고, 이는 FCOS 방법과 다름이 없다. single point에 spatial, scale constraint을 사용하기 때문에 anchor-free가 가능한 것이다.
Regression
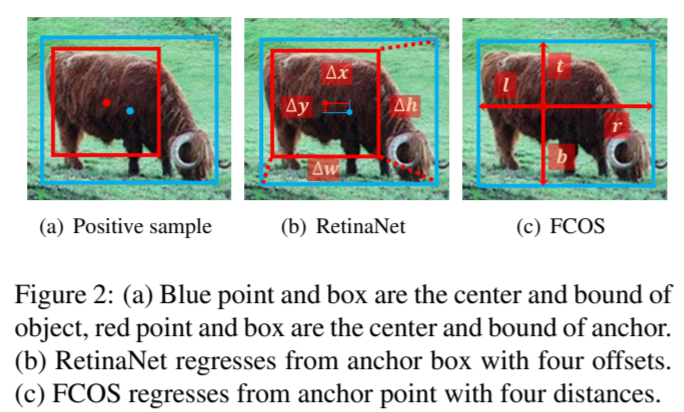
결정된 positive sample에 대해 bounding box를 찾는 regression이 이루어진다. 위 Figure 2를 보면 RetinaNet은 anchor box로 부터 4개의 offset에 대해 regression이 이루어진다. 반면에 FCOS는 점으로 부터 4개의 거리(distance)를 regression 한다. anchor-based와 anchor-free에는 regression의 시작이 box인지, point인지의 차이가 존재한다. 하지만 위 표를 보면 Box 또는 Point 모두 spatial, scale constraint를 적용하면 같은 성능(37.8% AP)을 얻었다. 이는 즉, regression starting status는 성능에 있어 본질적인 차이가 아닌 셈이다.
결론은 positive sampe, negative sample을 정의하는 방법이 가장 중요하다.
Adaptive Training Sample Selection (ATSS)
Algorithm

위의 결론을 토대로 how to define positive and negative training samples 에 대해 Adaptive Training Sample Selection을 제안한다. 이 방법은 hyperparameter 없이 robust 하다고한다. ATSS 방법은 위 알고리즘을 통해 알 수 있다.
- ground-truth box \(g\)의 positive sample 후보를 정한다. - (line 3 ~ 6)
- 각 pyramid level 마다 \(g\)와 가장 가까운 \(k\)개의 anchor box를 구한다.
- \(g\)의 center 그리고 anchor box의 center와의 L2 distance 이용
- 결국 하나의 ground-truth box \(g\)는 \(k \times L\)개의 positive sample 후보(\(C_g\))가 생긴다.
- ground truth \(g\)와 후보들(\(C_g\))간의 IoU를 계산한다. \(D_g\) 그 후 mean(\(m_g\))과 standard deviation(\(v_g\))을 구한다. - (line 7 ~ 9)
- ground truth \(g\)와의 IoU가 특정 threshold 값 보다 큰 후보를 최종 positive sample(\(P\))로 선택한다. - (line 11 ~ 15)
- positive sample의 center가 ground truth \(g\)안에 있는 경우에만 선택
- threshold \(t_g = m_g + v_g\)
- 하나의 anchor box가 여러 ground-truth box의 positive sample이 된다면, 가장 높은 IoU를 가진 쪽으로 선택된다.
- 전체 anchor box에서 positive sample로 선택 받지 못한 anchor들은 negative sample이 된다. - (line 17)
위 소개된 알고리즘에는 몇가지 특징이 있다.
- anchor box와 object 사이의 center distance based 후보 선택
- RetinaNet과 FCOS 모두 object와 anchor box(또는 point) 중심의 거리가 가까울 때 좋은 검출이 이루어진다.
- 따라서 center distnace 기반으로 후보를 선택한다.
- IoU threshold에 \(t_g = m_g + v_g\)를 사용
- \(m_g\)가 높으면 후보들이 high-quality이기 때문에 threshold 또한 높여야한다. 반대로 낮으면 low-quality이기 때문에 threshold를 낮게 줘야한다.
- \(v_g\)가 높으면 대부분의 pyramid level에서 검출이 가능하기 때문에 threshold를 높여야한다. 반대로 낮으면 특정 pyramid level에서만 검출이 가능하기 때문에 threshold를 낮춰야한다.
- 최종 positive sample을 뽑을 때 중심이 object에 있어야 선택
- 중심이 object 밖에 있는 anchor은 좋지 않은 후보이기 때문에 학습할 때 제거 되어야한다.
- hyperparameter-free
- 본 방법에는 hyperparameter가 \(k\) 하나 밖에 없다.
Verification
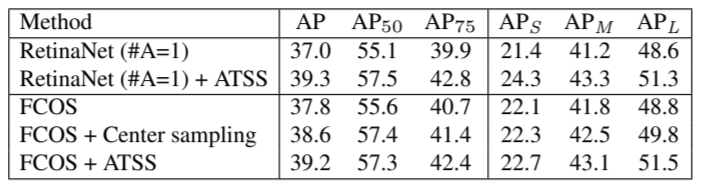
위 표를 보면 RetinaNet에 ATSS 기법을 적용할 때 더 좋은 성능을 내는 것을 확인 할 수 있다. 또한 ATSS 기법이 단순히 positive와 negative sample을 분류하는 기법이기 때문에 별다른 overhead 없이 cost-free 하다.
FCOS에는 두 버젼으로 적용하였다. Center sampling 기법은 ATSS의 lite한 버전이다. 이는 FCOS의 positive sample 고르는 방식과 본 논문의 방식을 합친 버전이다. 하지만 여기에는 아직 scale range라는 hyperparameter가 존재해서 높은 성능 향상을 이루어 내지는 못했다. 반면 ATSS를 적용하면 표에서 볼 수 있듯이 높은 성능향상이 이루어졌다. ATSS 방법은 hyperparameter의 사용을 최소한으로 했기 때문에 여러 metric에서 모두 좋은 성능을 냈다.
Analysis

본 논문에서는 단 한 가지의 hyperparameter을 사용한다. 바로 각 pyramid level에서 선택되어지는 positive sample 후보의 개수 \(k\)이다. 위 표를 보면, k를 3에서 19 까지 다양하게 변화시키며 실험을 하였다. \(k\)가 19인 경우 low-quality의 후보들이 선택되어 성능 감소가 있다. 마찬가지로 3인 경우, 매우 적은 후보만 추천되며 statistical 적으로 불안정하여(mean, standard deviation 사용 하였기 때문에), 성능 하락을 보인다. \(k\)가 7에서 17인 경우 성능에 큰 영향을 미치지 않았기 때문에 저자는 ATSS 모델이 꽤 robust(quite robust)하며, hyperparameter-free 라고 주장한다.
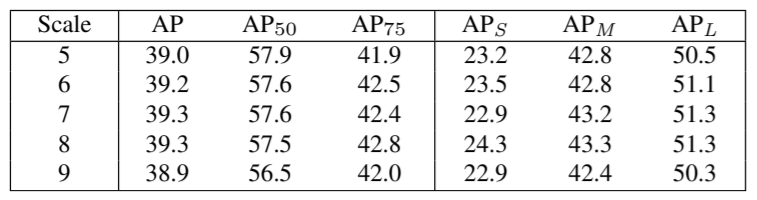
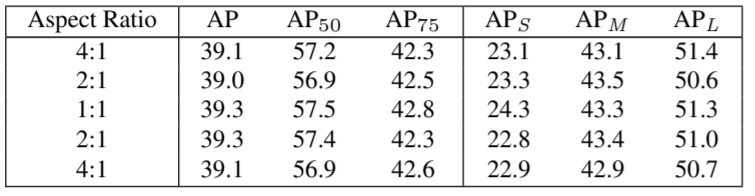
ATSS 모델 또한 anchor을 사용하기 때문에 anchor size에 대한 영향 또한 존재한다. 위 첫번째 표는 다양한 anchor size에 따른 성능이며, 두번째 표는 다양한 anchor 비율(ratio)에 따른 성능이다. 결과를 보면, ATSS 모델은 위 세팅에 민감하지 않음(insensitive)을 알 수 있으며, 이 또한 robust 하다고 주장한다.
Comparison
첨부하지 않은 Table 8을 보면, 여러 object detection 모델들과 성능 비교를 하는 거대한 표를 확인할 수 있다. 타 모델과 같은 backbone 모델을 사용했음에도 불구하고, 더 높은 성능을 얻어냈으며, 모든 종류의 detection 모델과 비교했을때 가장 높은 성능을 얻어 냈다고 한다. 또한, 본 논문에서 제안한 기법은 positive, negative sample을 정의하는 방법에 관련된 것이기 때문에, 거의 모든 타 기법에 호환되며 상호 보완적이라고 주장한다.
Discussion
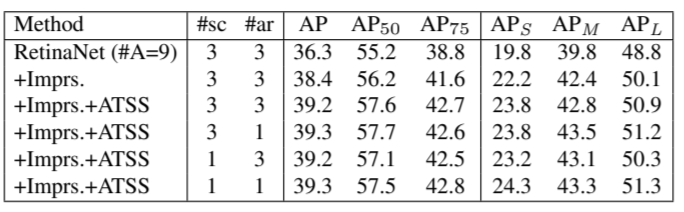
본 논문에서는 한 지역에 한 개의 anchor만 존재한 모델을 사용하여 실험을 진행하였다. 하지만 지역마다 anchor의 개수 또한 anchor-based, anchor-free detector의 차이이다. 위 표를 보면 기존 RetinaNet(#A=9)를 사용하면 논문에서 사용한 RetinaNet(#A=1) 보다 각 상황마다 높은 성능을 낼 수 있음을 알 수 있다. (e.g., RetinaNet(#A=9) vs RetinaNet(#A=1), RetinaNet(#A=9)+improve(Table 1) vs RetinaNet(#A=1)+improve(Table 1)) 하지만 ATSS 기법을 적용하면 (i.e., RetinaNet(#A=9)+improve+ATSS vs RetinaNet(#A=1)+improve+ATSS) 비슷한 성능을 얻을 수 있다. 즉 positive sample이 잘 뽑히기만 하면, anchor의 개수는 무의미하다 라는 결과이다. 저자는 이 기법에서는 지역 당 여러 개의 anchor은 바람직 하지 않고, 지역 당 여러개의 anchor를 쓰는 기법의 정확한 역할은 추가적인 연구가 필요하다고 첨언하였다.
Review
기존 기법 설명, 개념, 실험까지 매우매우 친절한 논문인 것 같다. 리뷰를 쓰면서도 저자의 생각을 빠짐없이 기록하려고 애썼던 것 같다. 그래서 리뷰가 매우 길어졌지만… object detection의 A-Z를 읽은 기분이 든다. object detection에 대해 연구하는 사람들에게 감히 추천 하고 싶은 논문..