Facebook Research에서 발표한 Object Detection 모델(Paper, OfficialCode)
Introduction
기존 Object Detection 모델인 경우 NMS와 같은 postprocessing step이 불가피하다. DETR(DEtection TRansformer)은 이러한 pipeline을 간단히 한 end-to-end 모델이다. 이름에도 알 수 있듯이 Transformer 기반의 encoder-decoder을 사용하여 동일한 예측을 없앴다. 또한 모든 object들을 하나의 set으로 생각 하고, ground-truth objects와 Bipartite Matching을 통해 loss function을 계산하였다.
Bipartite Matching Loss
DETR은 decoder을 통해 고정된 사이즈인 N개의 object를 예측 한다. 이 N개의 object와 ground-truth object간의 optimal bipartite matching이 이루어진다.
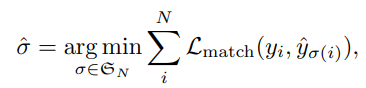
우선 N은 ground-truth object 수보다 넉넉하게 큰 수로 설정해놓고 예측한 N object set(\(\hat(y)\))의 permutation(순열) 중 ground-truth object set(\(y\)) 과의 \(L_{match}\)가 가장 작은 순열(\(\hat{\sigma}\))을 찾는다. ground-truth set은 N 사이즈 되도록 pad를 채워놓는다. 이 때 pad은 \(\phi\)(no object)를 의미한다.
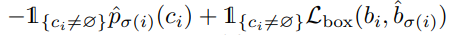
\(L_{match}\)은 각 쌍의 class와 box에 대한 pair-wise matching cost이다. c는 class label이며, b는 0과 1사이의 이미지 사이즈와 상대적인 box 중심, height 그리고 width로 이루어져있다. 그리고 p는 예측 확률이다. object가 있는 ground-truth와 그에 해당하는 쌍과의 matching cost이다. 이 때 위 matching cost는 anchor와 같은 역할을 한다고 한다. anchor을 이용하면 duplicate 될 수 있지만, 위 방법은 one-to-one 매칭으로 duplicate를 방지한다.
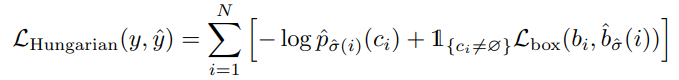
가장 적은 matching cost를 가진 \(\hat{\sigma}\)를 찾았으면, Hungarian loss를 계산한다. 위 loss를 보면 일반적인 object detection 모델에서 사용하는 loss와 유사하다. ground-truth가 background인 경우 class imbalance 때문에 가중치를 두어서 계산한다. OfficialCode를 보면 F.cross_entropy에 weight(self.empty_weight)을 둔 것을 알 수 있다.
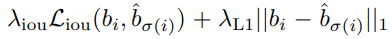
위는 \(L_{box}\)를 구하는 수식이다. 단순히 \(l_1\) loss 만을 사용하지 않고, scale-invariant한 gIoU loss를 함께 사용하였다.
DETR architecture
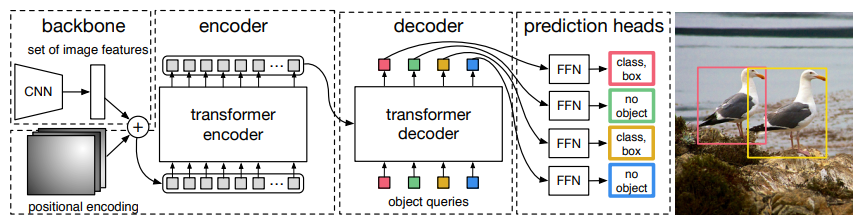
transformer를 설명하기 앞서 architecture는 위 figure와 같다. feature를 추출하는 backbone, Encoder-Decoder Transformer, FFN으로 구성되어 있다.
Transformer Encoder
encoder layer는 multi-head self-attention과 FFN으로 구성되어 있다. encoder은 input으로 sequence를 사용하기 때문에 Backbone의 output인 featuremap \(f \in R^{C \times H \times W}\)를 변형해야 한다. 우선 f에 1x1 convolution을 적용하여 \(z_0 \in R^{d \times H \times W}\)를 생성한다. 그리고 나서 위 \(z_0\)를 \(d \times HW\)로 바꾼다.
loss 계산할 때 permutation을 구하기 때문에, 이에 invariant 하도록 각 attention layer의 인풋으로 positional encoding을 추가한다.
Transformer Decoder
N object queries(처음에는 0으로 초기화)를 통해 output embedding이 생성된다. 이때 위에서 말한 대로 permutation-invariant를 위해 positional encoding이 사용되며, 각 embedding은 각기 다른 object를 의미한다. output은 FFN을 통해 N개의 box coordinates와 class label이 된다.
각 channel(d)은 각각 이미지의 다른 특징 정보를 갖고 있다. 이미지를 하나의 context, featuremap의 한 channel을 하나의 단어로 생각을 해야한다. 이 channel들은 self-attention을 통해, 전체 channel과 어떤 연관을 갖고 있는지에 대한 정보를 포함하여 encoding이 된다. 그 후 decoder에서는 각 encoder의 아웃풋(channels)에 attention을 적용하여, 적당한 특징들로 조합된 object를 예측하게 된다. 라는 것이 Transformer을 사용한 이유가 아닐까..
ground-truth의 object와 동일한 개수의 object를 예측할 수 있도록 FFN과 위의 Hungarian loss는 각 decoder layer에 계산되어진다(quxiliary decoding losses). 이때 FFN은 parameter을 공유된다.
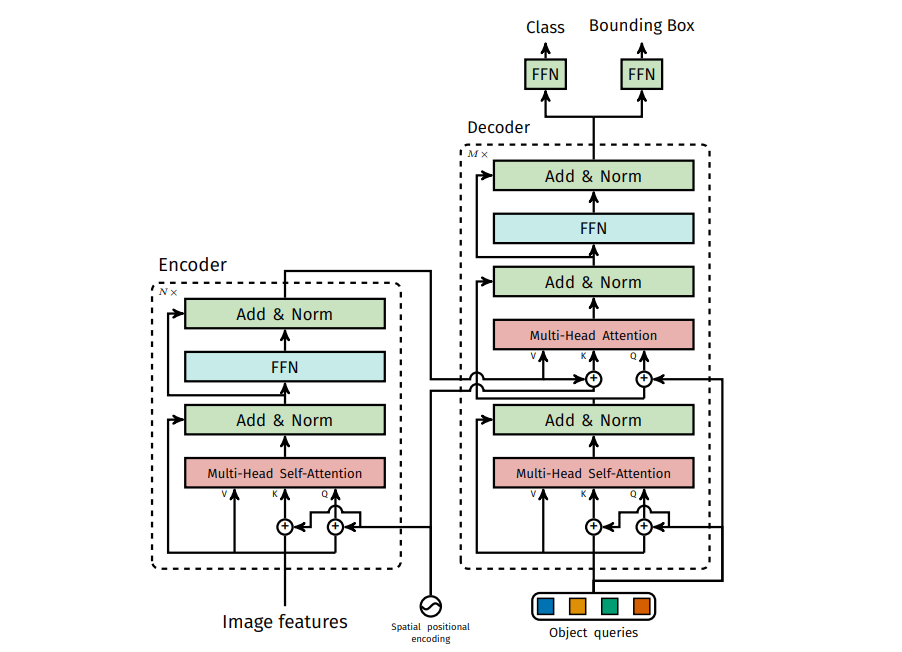
위 figure은 Appendix로 제공되는 DETR의 자세한 구조이다.
Review
깃헙 코드로 실제 학습을 진행해보았는데, 의미있는 성능을 얻기 힘들었다. 하지만 유행하는 Transformer 모델을 가장 직관적이게 사용한 모델인 것 같고, NMS과 같은 post-processing을 제외했다는 점이 흥미로웠다.