Problem
- 300시간의 비디오 속 모든 인물 비식별화 처리
- 모든 frame에 대해 처리
- Multi-Process
- ZMQ(ZeroMQ) 사용하여 통신
- GPU 2개가 달린 서버
- 4 프로세스 한계 (GPU 당 2 프로세스)
- 20개 영상(총 1시간) 전처리 -> 10시간 반 소모
- 단순 계산으로 300시간 영상 전처리 -> 약 3000시간(125일) 소모
- Deadline: 약 2주
Solving
- Kubernetes 서버 사용
- 여러개의 GPU 달린 서버
- Service, Job을 이용하여 Master, Worker 구현
- Master: 남은 일 체크 및 일 분배
- Worker: 받은 일 처리 완료 후 일 요청
Master
Flask를 사용하여 일 분배하는 master service를 구현
run.py
@app.route("/start")
def start():
"""
Params(GET):
- input_path=데이터 위치
- log_path=로깅 파일 위치
Descriptions:
- jobs = make_job_list(input_path)
- 주어진 input_path의 존재하는 모든 mp4 파일명 리스트를 생성(jobs)
"""
@app.route("/get_job")
def get_job():
"""
Descriptions:
- job = jobs.pop()
- return job
"""
@app.route("/fin_job")
def fin_job():
"""
Params(GET):
- job=해당 job
- status=상태 (1 or -1)
Descriptions:
- if not status == 1:
jobs.append(job)
"""
- worker들은 /get_job 을 통해 처리해야하는 영상 파일이름을 얻을 수 있다.
- 일이 끝난 worker는 /fin_job 을 통해 보고를 할 수 있다.
- 일이 마무리가 안된 경우 다시 jobs에 append 시킨다.
Dockerfile
FROM python:3.6
RUN pip install flask
COPY . /app
WORKDIR /app
ENTRYPOINT ["python"]
CMD ["run.py"]
master.yaml
apiVersion: v1
kind: Service
metadata:
name: blur-master-service
namespace: blur
spec:
selector:
app: blur-master
ports:
- name: http
protocol: TCP
port: AAAA
targetPort: BBBB
type: LoadBalancer
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: blur-master
namespace: blur
spec:
selector:
matchLabels:
app: blur-master
replicas: 1
template:
metadata:
labels:
app: blur-master
spec:
containers:
- name: blur-master
image: blur-master:latest
ports:
- containerPort: BBBB
volumeMounts:
- mountPath: /data
name: videos
volumes:
- name: videos
hostPath:
path: /videos/path/
- type: LoadBalancer: LoadBalancer을 이용하여 서비스
- replicas: 1: replica는 1로 두었다. jobs 리스트를 전역 변수로 사용하고 있기 때문에 독립적인 pod을 추가로 사용하게 되면 일을 중복으로 나눠주게 됨.
- volumes: 영상이 있는 스토리즈를 hostPath를 통해 마운트.
- 모든 워커 노드가 스토리지에 접근 할 수 있어야 함.
Worker
일이 없을 때 까지 master에게 일을 요청하는 worker을 구현. 주어진 일이 없으면 종료되어야 하므로 ReplicaSet 이 아닌 Job 을 이용.
run.py
# load DL model
MODEL_WEIGHT = os.getenv('MODEL_WEIGHT', "/MODEL/WEIGHT.pth")
detector = load_model(MODEL_WEIGHT)
# set ip&port of master service
master_ip = os.getenv('MASTER_IP', 'http://127.0.0.1:8080')
def get_job():
# master_ip + "/get_job" 으로 GET 요청
# return job
def set_fin_job(job, status):
# master_ip + '/fin_job?job={job}&status={status}'.format(job=job, status=status) 으로 GET 요청
def inference(job):
# Blur all faces in video
# blur 처리된 모든 frame과 기존 영상 속 오디오를 이용하여 새 영상 생성
def main():
while True:
job = get_job()
status = 0
if not job:
break
try:
# 새로운 영상 생성 성공시
inference(job)
status = 1
except:
# 실패시
status = -1
set_fin_job(job, status)
- 환경변수를 통해 모델의 가중치 파일(MODEL_WEIGHT)의 위치를 받는다.
- 환경변수를 통해 master(flask)에게 요청을 보낼 수 있는 url을 받는다.
- 일 요청 -> 일 처리 -> 일 보고
- 일이 없으면 종료
Dockerfile
FROM pytorch/pytorch:1.4-cuda10.1-cudnn7-runtime
RUN apt-get update
RUN apt-get install -y libgl1-mesa-dev
RUN apt-get install -y libgtk2.0-dev
RUN apt-get install -y ffmpeg
RUN pip install opencv-python cmake
RUN pip install dlib ujson
COPY . /app
WORKDIR /app
ENTRYPOINT ["python"]
CMD ["run.py"]
worker.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: blur-worker
namespace: blur
spec:
parallelism: 10
template:
spec:
containers:
- name: blur-worker
image: blur-worker:latest
env:
- name: MASTER_IP
value: "http://blur-master-service:AAAA"
- name: MODEL_WEIGHT
value: "/MODEL/WEIGHT.pth"
- name: OUTPUT
value: "/OUTPUT/PATH"
resources:
limits:
nvidia.com/gpu: 1
volumeMounts:
- mountPath: /data
name: videos
restartPolicy: Never
volumes:
- name: videos
hostPath:
path: /videos/path/
backoffLimit: 2
- kind: Job:
- ReplicaSet의 경우 restartPolicy: Always 만 사용해야함
- 일이 끝난 worker가 계속 재실행되어서 자원 낭비
- Job 컨트롤러를 이용 -> restartPolicy: Never
- parallelism: 몇개의 pod이 병렬적으로 작업을 할 것인지. ReplicaSet의 replicas 와 같은 개념이다.
- env:: Master_IP, MODEL_WEIGHT, OUTPUT 환경변수를 사용하여 코드 수정 없이 yaml 파일만 수정할 수 있도록
- nvidia.com/gpu: 1: 모델당 GPU 1개의 메모리면 충분 하기 때문에 limits을 걸어놓음
- volumes: 영상이 있는 스토리지를 hostPath를 통해 마운트.
- 모든 워커 노드가 스토리지에 접근 할 수 있어야 함.
실행 결과
master 실행 결과

worker 실행 결과
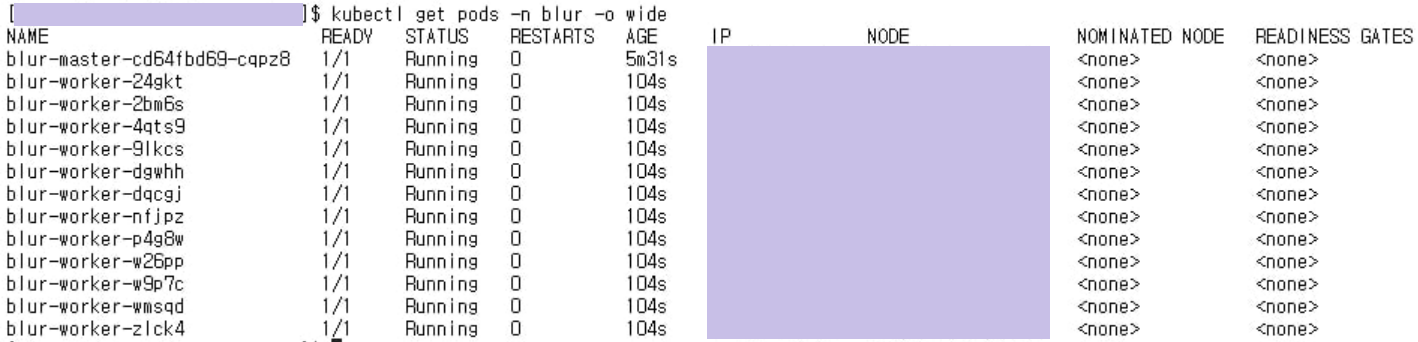
전처리 결과
- 20개 영상(총 1시간) 전처리 -> 1시간 반 소모
추가
기존 worker.yaml
limits:
nvidia.com/gpu:1
위와 같이 gpu를 한개로 제한을 해버리면 사용할 수 있는 gpu 개수 만큼만 parallelism를 선택할 수 있다. 따라서 GPU Share Scheduler (GitHub)을 사용하였다.
변경된 worker.yaml
limits:
aliyun.com/gpu-mem: 3
- gpu-mem을 설정하여 pod들이 gpu를 공유하여 해당 memory 만큼만 사용.
- 여기서 1은 1GB.
- 전처리 시간 1/2 단축.