- 프로젝트 소개 및 정보
- MLOps System Design
- CI/CD using Github Action
- CT using Kubeflow pipelines - 1
- CT using Kubeflow pipelines - 2
- Serving TorchServe in kubeflow pipelines - 1
- Serving TorchServe in kubeflow pipelines - 2
- Trigger using Slack
System Design
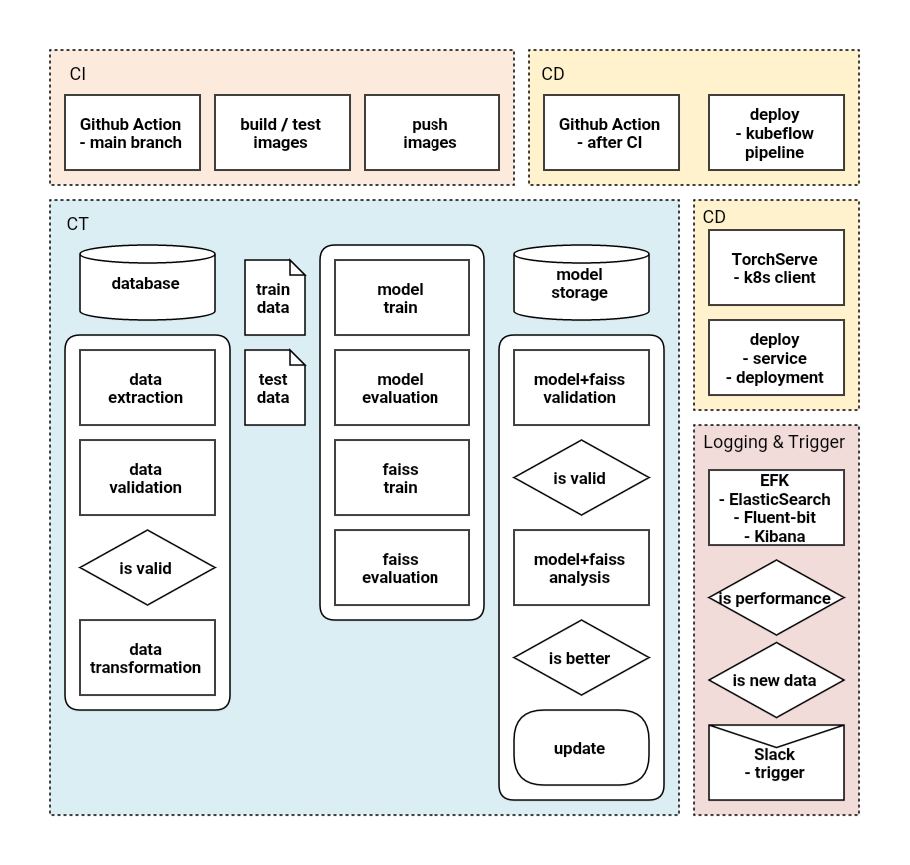
ml-system-design-pattern와 MLOps를 참고하여 이 프로젝트의 전체 시스템을 설계하였다.
설계하면서 가장 중점에 둔 것은 CT pipelines 이다. 일반적인 DevOps와 달리 MLOps는 CT라는 과정을 거쳐야한다. 이에 다섯가지 필수 구성요소를 집어넣었다. URL
- Prepare & Integrate Data
- data extraction
- data validation
- Data Preparation(data transforms)
- Feature Engineering
- train data
- test data
- Model Training & Model Evaluation
- model train
- model evaluate
- model validation
- model analysis
- Hyper Parameter Tuning
- katlib
- Model Store
- Model Storage
외부 서버 및 스토리지를 사용하지 못하고, node가 하나인 minikube를 사용하기 때문에 Model Store나 Fetaure Store의 경우 hostpath volume을 사용하였다. 모두 추후 포스팅에서 다룰 것이다…!
학습이 완료 된 후 서비스 배포를 할 때 ArgoCD(url)를 사용할까 고민을 했다. 하지만 요즘 핫한? 기술을 사용해보고 싶어서 TorchServe와 KFServing을 사용하였다. TorchServe를 사용하기로 마음 먹은 순간 CT의 파이프라인 또한 구축하기 쉬워졌다.
이 프로젝트는 이미지를 임베딩 하는 모델(PyTorch)과 kNN 모델(Faiss), 총 두 모델로 구성되어 있다. 따라서 각자 학습 후, 배포시 모델 관련 코드를 재사용 해야했다. 최대한 코드 재사용을 피하는 pipeline을 구축하고 싶어서 고민이 많았다. 그리고.. Torchscript(jit)가 이 고민을 해결해주었다. 자세한 내용은 추후 포스팅에서…!
배포가 완료된 후에도, 지속적인 로그 수집 및 monitoring을 구축하려고 한다. 그리고 이를 trigger 할 수 있도록 구축 하고자 한다. 사실 지금 Logging&Monitoring은 구축 하기 전이라.. 자세한 내용을 말할 수가 없다..
References
- Kubernetes
- Kubeflow
- kubernetes
- kubeflow
- MLOps