- 프로젝트 소개 및 정보
- MLOps System Design
- CI/CD using Github Action
- CT using Kubeflow pipelines - 1
- CT using Kubeflow pipelines - 2
- Serving TorchServe in kubeflow pipelines - 1
- Serving TorchServe in kubeflow pipelines - 2
- Trigger using Slack
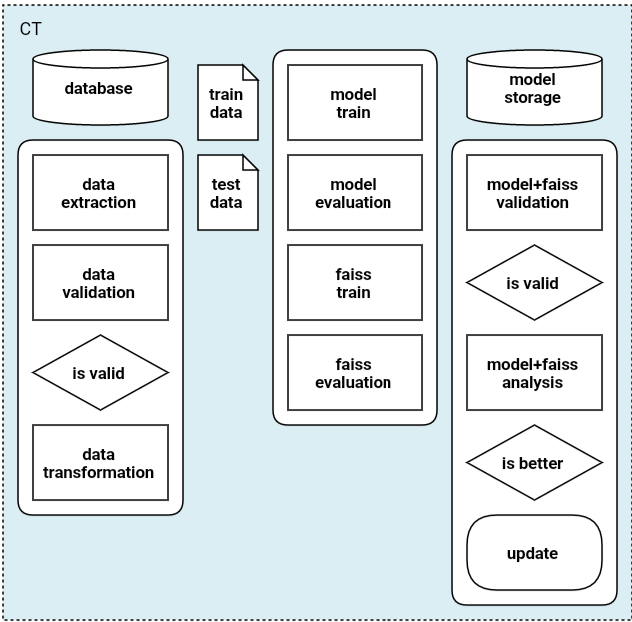
이 포스팅에는 위의 CT 단계에 관련된 내용을 담고 있다.
CT는 Kubeflow의 pipelines(url)을 통해 구현하였다. kubeflow pipelines은 kubeflow 의 여러 기능 중 하나로, end-to-end ML 워크플로우를 만들고, 배포할 수 있는 가장 중요한 기능이다. 특히 python SDK (url)가 매우 잘되어있어서, 사용하기가 쉽다. 사용법은 Doc을 통해 익힐 수 있다.
CT 파이프라인을 구현하면서 배포 과정(KFServing) 개발중 버전 문제로 가장 애먹었다. 여러 시행착오 끝에 microk8s로 설치된 Kubeflow v1.2 를 선택하였고, KFServing 대신 Kubernetes Client Python SDK를(Github) 이용한 TorchServe를 통해 Serving을 하였다.
- Kubeflow v1.0
- Kubeflow v1.2
- microk8s로 설치 -microk8s (설치시 –container-runtime=docker 설정을 해주어야 kfp file_outputs 사용 가능 - Github Issue)
- KFServing v1beta1 사용 가능(torchserve는 v0.5.0 부터 지원 -> KFServing, knative-serving 버전 업 필요)
한창 개발 중인 오픈소스의 버전 문제는 항상 어렵다..
거대한 데이터인 척, mnist로 MLOps 구축하기 프로젝트의 경우 총 7개의 단계로 CT를 구성하였다. 코드는 Github에서 확인이 가능하다.
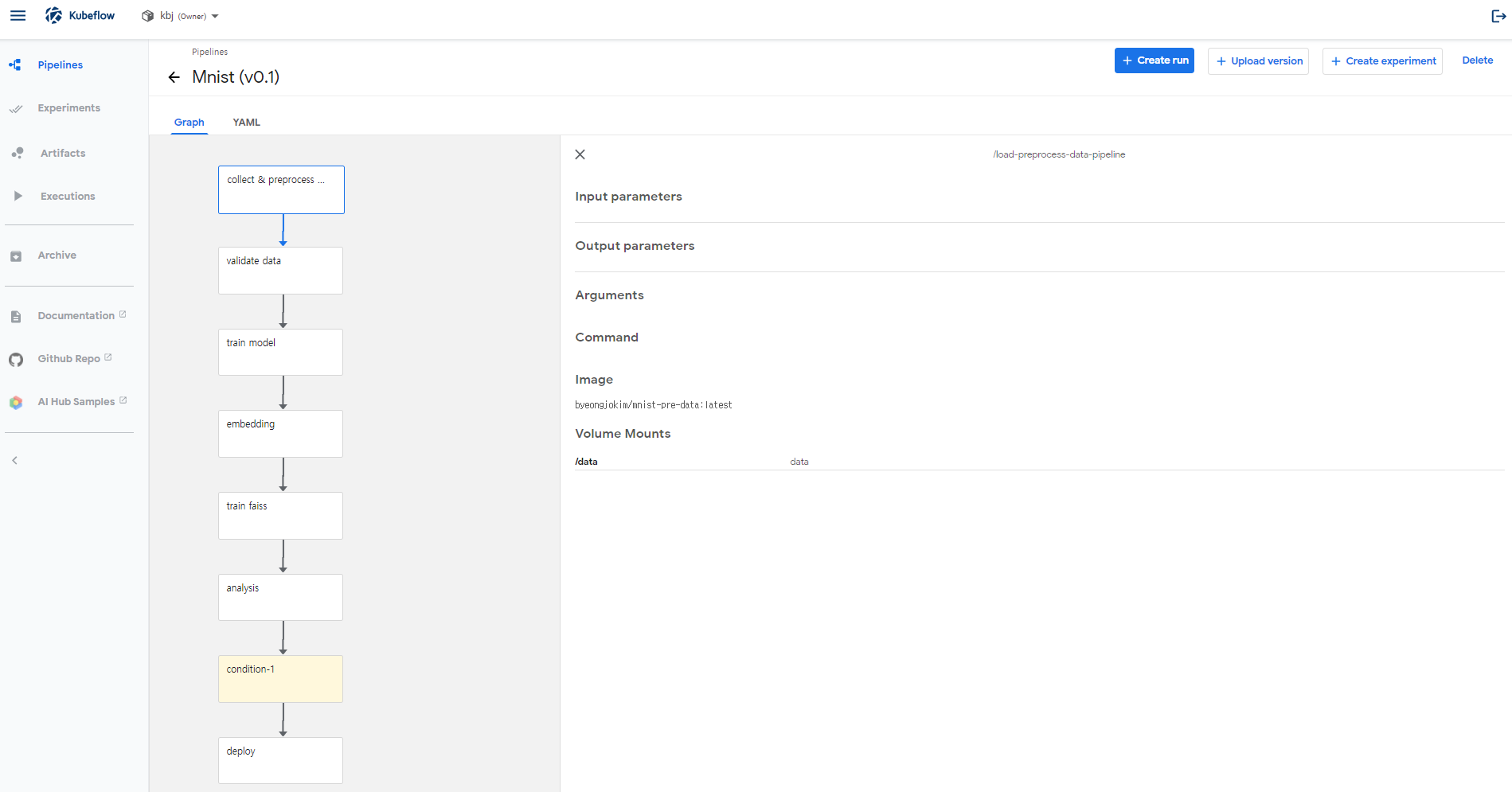
각 단계에서 수행하는 기능과, 고려했던 사항들은 다음과 같다.
- 0_data
- 기능:
- data 수집
- 전처리 후 npy 저장(train/test/validate)
- 고려:
- 전체 dataset 메모리에 한번에 올리지 않도록 제한 -> args.npy_interval 사용하여 데이터 나누어 저장
- embedding 학습에 사용되는 데이터와 faiss 학습 시 사용되는 데이터 구분
- 기능:
- 1_validate_data
- 기능:
- 전처리된 npy 파일 검증
- 고려:
- shape, type 등 제대로 전처리 되었는지 확인
- 기능:
- 2_train_model
- 기능:
- embedding 모델 학습
- 고려:
- Arcface 사용하여 학습
- multi gpu 사용
- 학습 완료된 모델 torch.jit.script 로 저장 -> 3_embedding, 5_analysis_model에서 model Class 코드 재사용 없이 load
- 기능:
- 3_embedding
- 기능:
- faiss에 사용될 데이터 embedding 후 npy 저장
- 고려:
- 코드 재사용 없이 model.pt load
- 기능:
- 4_train_faiss
- 기능:
- embedding npy로 faiss 학습
- 고려:
- faiss index: faiss_index.bin 저장
- embedding과 매칭되는 label: faiss_label.json 저장
- 기능:
- 5_analysis_model
- 기능:
- 전체 모델(embedding + faiss) 성능 평가
- 고려:
- mlpipeline-metrics, mlpipeline-ui-metadata 로 시각화
- class 별 accuracy 측정 (confusion matrix)
- dsl.Condition 사용하여 배포할지 결정
- 기능:
- 6_deploy
- 기능:
- 모델 버전 관리
- config 관리
- Service, Deployment 배포
- 고려:
- torch-model-archiver, torchserve 사용
- replicaset 사용
- rolling update
- 기능:
각각 스텝의 pvc, 순서, output 등의 설정은 다음 포스팅에서 소개할 예정이다.