- 프로젝트 소개 및 정보
- MLOps System Design
- CI/CD using Github Action
- CT using Kubeflow pipelines - 1
- CT using Kubeflow pipelines - 2
- Serving TorchServe in kubeflow pipelines - 1
- Serving TorchServe in kubeflow pipelines - 2
- Trigger using Slack
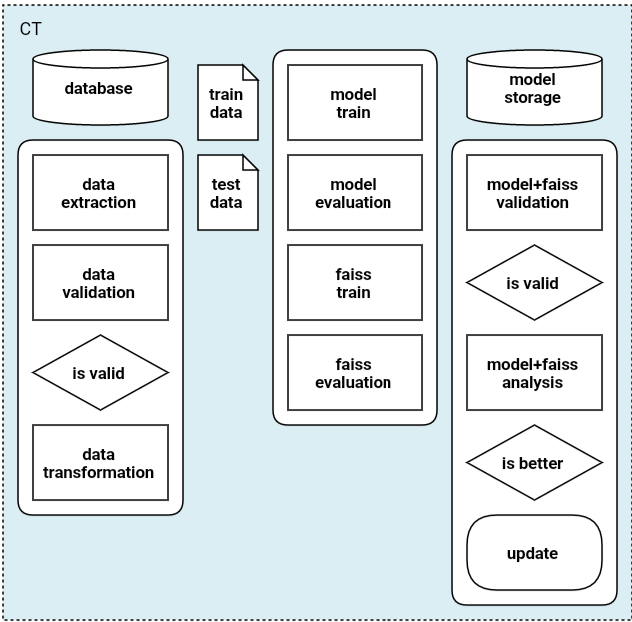
이 포스팅에는 위의 CT 단계에 관련된 내용을 담고 있다.
kubeflow pipelines는 각 단계에 맞는 k8s 파드를 실행시킨다. 각 파드는 설정된 컨테이너 이미지를 통해 작동이 된다. 그리고 이 파이프라인을 설계하기 위해 Python SDK(KFP docs)을 사용하였다. KFP는 pip를 통해 쉽게 설치가 가능하다.
@dsl.pipeline(
name="mnist using arcface",
description="CT pipeline"
)
def mnist_pipeline():
data_0 = dsl.ContainerOp(
name="load & preprocess data pipeline",
image="byeongjokim/mnist-pre-data:latest",
).set_display_name("collect & preprocess data")\
.apply(onprem.mount_pvc("data-pvc", volume_name="data", volume_mount_path="/data"))
...
위는 KFP로 설계한 pipeline.py의 일부이다. @dsl.pipeline 데코레이션을 통해 리소스 메타정보를 입력할 수 있다. 그리고 컨테이너 이미지 기반의 스텝은 ContainerOP docs로 생성한다. kfp는 ContainerOP 뿐만 아니라, ResourceOp, VolumeOp 등 다양한 파이프라인 스텝을 생성할 수 있다.
ContainerOp
- name: 컴포넌트 이름
- image: 컨테이너 이미지
- command: 컨테이너 실행 명령어
- arguments: 컨테이너 실행 인자값
- file_outputs: 외부로 노출할 컨테이너 실행 결과
- pvolumes: Volume 마운트
- …
ContainerOp는 주로 위의 파라미터를 사용한다. 자세한 내용은 docs를 참고하면 된다.
보통 kfp 예제를 보면, VolumeOp로 pvc를 생성 및 설정 후 ContainerOP의 pvolumes 파라미터를 이용하여 mount 시킨다. 또는 ContainerOp의 add_volume과 add_volume_mount method를 이용한다. 하지만 onprem docs를 사용하면 쉽게 mount 시킬 수 있다. 본 프로젝트는 실행할때마다 pvc를 만들지 않고, data, train-model, deploy-model 역할을 하는 pv/pvc를 미리 세팅 후 파이프라인을 개발하였다. 서버 한계로 인해 NFS, gcp 등의 스토리지를 사용하지 않았고, pv에 hostpath를 연결하여 사용하였다.
analysis = dsl.ContainerOp(
name="analysis total",
image="byeongjokim/mnist-analysis:latest",
file_outputs={
"confusion_matrix": "/confusion_matrix.csv",
"mlpipeline-ui-metadata": "/mlpipeline-ui-metadata.json",
"accuracy": "/accuracy.json",
"mlpipeline_metrics": "/mlpipeline-metrics.json"
}
).set_display_name('analysis').after(train_faiss)\
.apply(onprem.mount_pvc("data-pvc", volume_name="data", volume_mount_path="/data"))\
.apply(onprem.mount_pvc("train-model-pvc", volume_name="train-model", volume_mount_path="/model"))
위는 모델을 평가하는 step의 ContainerOp이다. file_outputs을 보면 각 평가 지표가 저장된 csv, json 파일을 외부로 노출하게 된다. 저 artifact들을 kubeflow dashboard에서 확인하고 싶으면 “mlpipeline-ui-metadata”, “mlpipeline_metrics”로 명명해야한다. 또한, 형식을 지켜서 파일을 저장해야한다. 자세한 내용은 kubeflow Visualize Results에서 확인 가능하다.
그리고 .after()을 통해 어떤 step 후에 실행되는 step인지도 설정해줄 수 있다. .after()을 설정해놓지 않으면 ContainerOp가 순서 없이 병렬적으로 실행이 된다.
with dsl.Condition(analysis.outputs["accuracy"] > baseline) as check_deploy:
deploy = dsl.ContainerOp(
name="deploy mar",
image="byeongjokim/mnist-deploy:latest",
).set_display_name('deploy').after(analysis)\
.apply(onprem.mount_pvc("train-model-pvc", volume_name="train-model", volume_mount_path="/model"))\
.apply(onprem.mount_pvc("deploy-model-pvc", volume_name="deploy-model", volume_mount_path="/deploy-model"))
위는 analysis step에서 생성된 아웃풋 accuracy을 이용하여 배포를 할지 결정하는 부분이다. dsl.Condition을 사용하여 특정 threshold 보다 큰 accuracy 성능일 때에만 deploy ContainerOp가 실행이 된다.
if __name__=="__main__":
host = "http://xxx.xxx.xxx.xxx:xxxx/pipeline"
namespace = "kbj"
pipeline_name = "Mnist"
pipeline_package_path = "pipeline.zip"
version = "v0.1"
experiment_name = "For Develop"
run_name = "from collecting data to deploy"
client = kfp.Client(host=host, namespace=namespace)
kfp.compiler.Compiler().compile(mnist_pipeline, pipeline_package_path)
pipeline_id = client.get_pipeline_id("Mnist")
if pipeline_id:
client.upload_pipeline_version(pipeline_package_path=pipeline_package_path, pipeline_version_name=version, pipeline_name=pipeline_name)
else:
client.upload_pipeline(pipeline_package_path=pipeline_package_path, pipeline_name=pipeline_name)
experiment = client.create_experiment(name=experiment_name, namespace=namespace)
run = client.run_pipeline(experiment.id, run_name, pipeline_package_path)
위는 설정한 pipeline을 kubeflow에 올리는 코드 부분이다. 우선 host로 원격 kubernetes에 파이프라인을 올릴 수 있게 설정을 해놓았다. 또한 namespace를 통해 파이프라인 실험들을 관리할 수 있다. 중요한 코드의 설명은 아래와 같다.
- client = kfp.Client(host=host, namespace=namespace)
- host와 namespace를 설정하여, 원격 k8s의 kubeflow에 원하는 namespace로 연결
- kfp.compiler.Compiler().compile(mnist_pipeline, pipeline_package_path)
- 설정한 파이프라인을 pipeline.zip으로 컴파일
- client.upload_pipeline(pipeline_package_path=pipeline_package_path, pipeline_name=pipeline_name)
- 새로운 파이프라인으로 업로드
- pipeline_id = client.get_pipeline_id(“Mnist”)
- 파이프라인 이름으로 파이프라인 id 검색
- client.upload_pipeline_version(pipeline_package_path=pipeline_package_path, pipeline_version_name=version, pipeline_name=pipeline_name)
- 기존에 존재하는 파이프라인에 버전을 달리하여 업로드
- experiment = client.create_experiment(name=experiment_name, namespace=namespace)
- 새로운 실험 생성
- run = client.run_pipeline(experiment.id, run_name, pipeline_package_path)
- 생성된 실험 시작
CI/CD using Github Action 에서 설명했듯이 github action에서 pipeline.py를 실행하도록 하였다. 즉 코드 수정 후 github에 master branch로 push하면, pipelines를 이용하여 학습 후 배포가 이루어지게 된다.
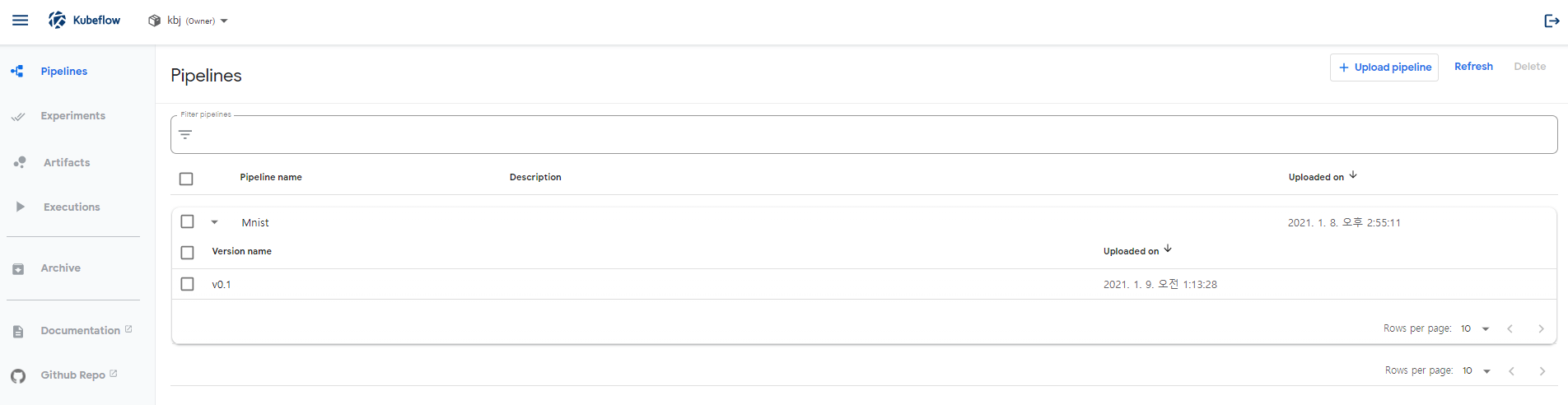
생성된 파이프라인
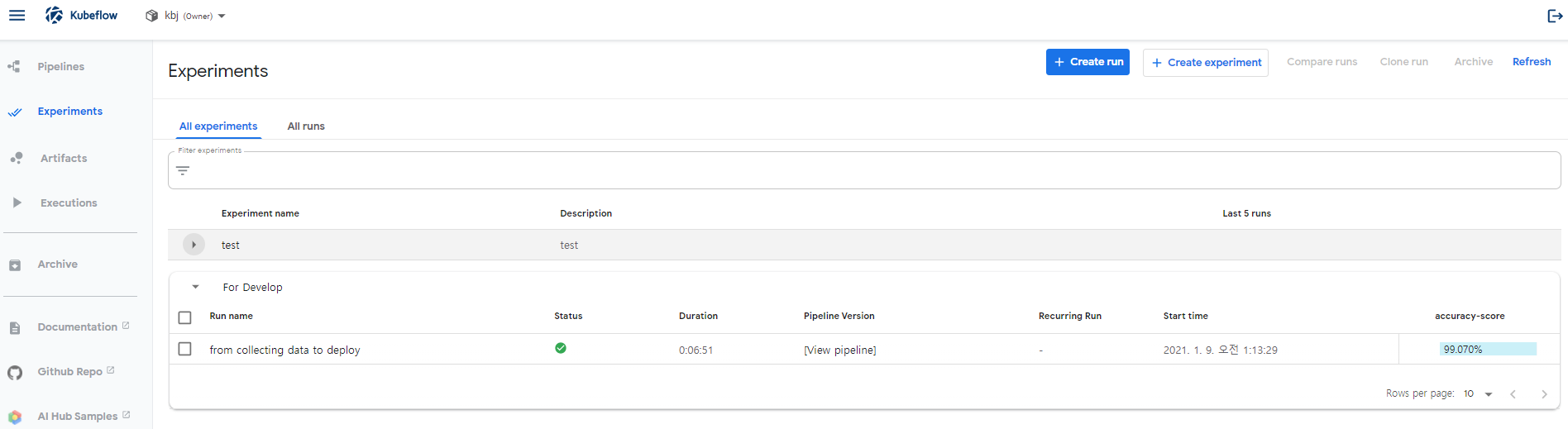
생성/완료 된 실험
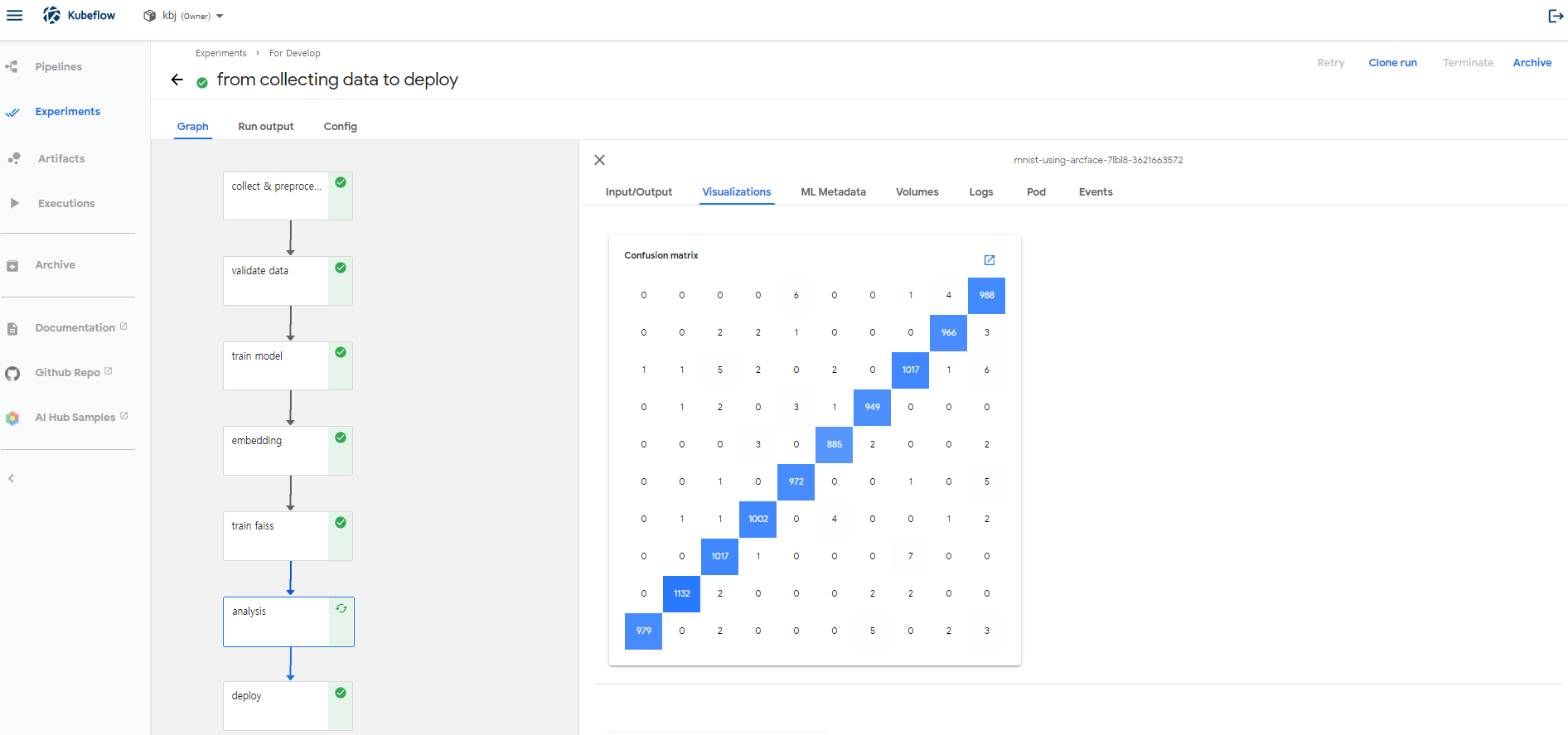
analysis step의 output인 Confusion Matrix 시각화
아래는 pipeline.py 전체 이다.
import os
import kfp
import kfp.components as comp
from kfp import dsl
from kfp import onprem
from kubernetes import client as k8s_client
@dsl.pipeline(
name="mnist using arcface",
description="CT pipeline"
)
def mnist_pipeline():
data_0 = dsl.ContainerOp(
name="load & preprocess data pipeline",
image="byeongjokim/mnist-pre-data:latest",
).set_display_name('collect & preprocess data')\
.apply(onprem.mount_pvc("data-pvc", volume_name="data", volume_mount_path="/data"))
data_1 = dsl.ContainerOp(
name="validate data pipeline",
image="byeongjokim/mnist-val-data:latest",
).set_display_name('validate data').after(data_0)\
.apply(onprem.mount_pvc("data-pvc", volume_name="data", volume_mount_path="/data"))
train_model = dsl.ContainerOp(
name="train embedding model",
image="byeongjokim/mnist-train-model:latest",
).set_display_name('train model').after(data_1)\
.apply(onprem.mount_pvc("data-pvc", volume_name="data", volume_mount_path="/data"))\
.apply(onprem.mount_pvc("train-model-pvc", volume_name="train-model", volume_mount_path="/model"))
embedding = dsl.ContainerOp(
name="embedding data using embedding model",
image="byeongjokim/mnist-embedding:latest",
).set_display_name('embedding').after(train_model)\
.apply(onprem.mount_pvc("data-pvc", volume_name="data", volume_mount_path="/data"))\
.apply(onprem.mount_pvc("train-model-pvc", volume_name="train-model", volume_mount_path="/model"))
train_faiss = dsl.ContainerOp(
name="train faiss",
image="byeongjokim/mnist-train-faiss:latest",
).set_display_name('train faiss').after(embedding)\
.apply(onprem.mount_pvc("data-pvc", volume_name="data", volume_mount_path="/data"))\
.apply(onprem.mount_pvc("train-model-pvc", volume_name="train-model", volume_mount_path="/model"))
analysis = dsl.ContainerOp(
name="analysis total",
image="byeongjokim/mnist-analysis:latest",
file_outputs={
"confusion_matrix": "/confusion_matrix.csv",
"mlpipeline-ui-metadata": "/mlpipeline-ui-metadata.json",
"accuracy": "/accuracy.json",
"mlpipeline_metrics": "/mlpipeline-metrics.json"
}
).set_display_name('analysis').after(train_faiss)\
.apply(onprem.mount_pvc("data-pvc", volume_name="data", volume_mount_path="/data"))\
.apply(onprem.mount_pvc("train-model-pvc", volume_name="train-model", volume_mount_path="/model"))
baseline = 0.8
with dsl.Condition(analysis.outputs["accuracy"] > baseline) as check_deploy:
deploy = dsl.ContainerOp(
name="deploy mar",
image="byeongjokim/mnist-deploy:latest",
).set_display_name('deploy').after(analysis)\
.apply(onprem.mount_pvc("train-model-pvc", volume_name="train-model", volume_mount_path="/model"))\
.apply(onprem.mount_pvc("deploy-model-pvc", volume_name="deploy-model", volume_mount_path="/deploy-model"))
if __name__=="__main__":
host = "http://xxx.xxx.xxx.xxx:xxxx/pipeline"
namespace = "kbj"
pipeline_name = "Mnist"
pipeline_package_path = "pipeline.zip"
version = "v0.2"
experiment_name = "For Develop"
run_name = "serving version {}".format(version)
client = kfp.Client(host=host, namespace=namespace)
kfp.compiler.Compiler().compile(mnist_pipeline, pipeline_package_path)
pipeline_id = client.get_pipeline_id(pipeline_name)
if pipeline_id:
client.upload_pipeline_version(pipeline_package_path=pipeline_package_path, pipeline_version_name=version, pipeline_name=pipeline_name)
else:
client.upload_pipeline(pipeline_package_path=pipeline_package_path, pipeline_name=pipeline_name)
experiment = client.create_experiment(name=experiment_name, namespace=namespace)
run = client.run_pipeline(experiment.id, run_name, pipeline_package_path)