- 프로젝트 소개 및 정보
- MLOps System Design
- CI/CD using Github Action
- CT using Kubeflow pipelines - 1
- CT using Kubeflow pipelines - 2
- Serving TorchServe in kubeflow pipelines - 1
- Serving TorchServe in kubeflow pipelines - 2
- Trigger using Slack
이 포스팅에는 위의 CD 단계 중 TorchServe에 관련된 내용을 담고 있다.
이전 포스팅에서 압축된 mar 파일을 배포하기 위해서는 우선 config.properties 설정 파일이 필요하다. 다양한 설정은 url에서 확인 가능하다.
inference_address=http://0.0.0.0:8082
management_address=http://0.0.0.0:8083
metrics_address=http://0.0.0.0:8084
job_queue_size=100
install_py_dep_per_model=true
load_models=all
inference/management/metrics 주소와 포트를 설정 한다. 그리고 python package(requirements.txt)를 설치 하기 위해 install_py_dep_per_model=true을 설정한다.
TorchServe
torchserve --start --model-store /home/model-server/shared/model-store/ --ts-config /home/model-server/shared/config/config.properties
TorchServe을 사용하기 위해서는 –model-store, –ts-config 경로 설정이 필요하다. 그리고 각 경로에 mar파일과 config.properties파일이 존재해야한다.
k8s 서버에 TorchServe를 배포를 할때는 TorchServe helm 처럼 deployment와 service yaml 파일이 필요하다. 하지만 이 프로젝트는 kubeflow pipelines의 deploy step에서 k8s로의 배포가 이루어져야 하기 때문에, kubernetes client Github을 이용하여 배포를 한다.
from kubernetes import client, config
config.load_incluster_config()
k8s 내부에서 돌아가는 kubeflow pipelines pod에서 k8s에 접근 하기 위해서는 load_incluster_config() 설정이 필요하다.
k8s_apps_v1 = client.AppsV1Api()
template = client.V1PodTemplateSpec(
metadata=client.V1ObjectMeta(
labels={
"app":"torchserve",
"app.kubernetes.io/version":version
}
),
spec=client.V1PodSpec(
volumes=[
client.V1Volume(
name="persistent-storage",
persistent_volume_claim=client.V1PersistentVolumeClaimVolumeSource(
claim_name="serving-model-pvc"
)
)
],
containers=[
client.V1Container(
name="torchserve",
image="pytorch/torchserve:0.3.0-cpu",
args=["torchserve", "--start", "--model-store", "/home/model-server/shared/model-store/", "--ts-config", "/home/model-server/shared/config/config.properties"],
image_pull_policy="Always",
ports=[
client.V1ContainerPort(
name="ts",
container_port=args.pred_port
),
client.V1ContainerPort(
name="ts-management",
container_port=args.manage_port
),
client.V1ContainerPort(
name="ts-metrics",
container_port=args.metric_port
)
],
volume_mounts=[
client.V1VolumeMount(
name="persistent-storage",
mount_path="/home/model-server/shared/"
)
],
resources=client.V1ResourceRequirements(
limits={
"cpu":1,
"memory":"4Gi",
"nvidia.com/gpu": 0
},
requests={
"cpu":1,
"memory":"1Gi",
}
)
)
]
)
)
deployment = client.V1Deployment(
api_version="apps/v1",
kind="Deployment",
metadata=client.V1ObjectMeta(
name="torchserve",
labels={
"app":"torchserve",
"app.kubernetes.io/version":version
}
),
spec=client.V1DeploymentSpec(
replicas=2,
selector=client.V1LabelSelector(
match_labels={"app":"torchserve"}
),
strategy=client.V1DeploymentStrategy(
type="RollingUpdate",
rolling_update=client.V1RollingUpdateDeployment(
max_surge=1,
max_unavailable=1,
)
),
template=template
)
)
try:
k8s_apps_v1.create_namespaced_deployment(body=deployment, namespace=args.namespace)
print("[+] Deployment created")
except:
k8s_apps_v1.replace_namespaced_deployment(name="torchserve", namespace=args.namespace, body=deployment)
print("[+] Deployment replaced")
위는 kubernetes client python SDK를 이용하여 만든 deployment 선언 부분이다. deployment에 RollingUpdate를 적용해서, 배포된 deployment가 있으면 새로운 deployment로 replace 되도록 하였다. client가 사용하는 여러 method는 Github에서 확인 할 수 있다. 각 method의 인자 값을 적절하게 설정하였다.
여기서 중요한 점은 모델과 config 파일이 존재하는 PV, PVC 이다. deployment에 적절한 path로 mount를 시켜야, 그 path를 통해 TorchServe에서 모델과 config 파일을 읽을 수 있다.
이 프로젝트에는 hostPath로 연결된 PV를 사용하였고, /home/model-server/shared/에 mount 시켰다. TorchServe는 /home/model-server/shared/model-store, /home/model-server/shared/config 폴더안의 파일을 읽고 배포가 이루어진다.
k8s_core_v1 = client.CoreV1Api()
service = client.V1Service(
api_version="v1",
kind="Service",
metadata=client.V1ObjectMeta(
name="torchserve",
labels={
"app":"torchserve"
}
),
spec=client.V1ServiceSpec(
type="LoadBalancer",
selector={"app":"torchserve"},
ports=[
client.V1ServicePort(
name="preds",
port=args.pred_port,
target_port="ts"
),
client.V1ServicePort(
name="mdl",
port=args.manage_port,
target_port="ts-management"
),
client.V1ServicePort(
name="metrics",
port=args.metric_port,
target_port="ts-metrics"
)
]
)
)
try:
k8s_core_v1.create_namespaced_service(body=service, namespace=args.namespace)
print("[+] Service created")
except:
print("[+] Service already created")
위는 service 선언 부분이다. service는 적절한 pod에 endpoint를 연결만 해주면 되는 resource이기 때문에 따로 update 관련 설정을 안해주었다.
Deploy step in pipelines
kubeflow 파이프라인의 deploy step에서 작동되는 기능은 다음과 같다.
- torch-model-archiver을 통해 mar 파일 생성
- 이미 생성된 mar 파일 관리 (한번에 3개 초과의 모델 load 되지 않도록)
- config 파일 생성
- kubernetes client Python SDK를 이용한 Service, Deployment 배포
아래는 길지만.. deploy ContainerOp 속 실행되는 코드이다.
import os
import argparse
from datetime import datetime
from kubernetes import client, config
import yaml
import requests
from glob import glob
def management_model_store(path, prefix, max_num_models):
backup_foldername = "backup"
backup_path = os.path.join(path, backup_foldername)
if not os.path.isdir(backup_path):
os.mkdir(backup_path)
print('[+] Mkdir backup path:', backup_path)
mar_files = glob(os.path.join(path, "{}*.mar".format(prefix)))
mar_files.sort()
mar_files = mar_files[:-1*max_num_models]
cmd = "mv {} {}".format(" ".join(mar_files), backup_path)
print(cmd)
os.system(cmd)
def archive(args, version):
model_name_version = args.model_name+"_"+version
if not os.path.isdir(args.export_path):
os.mkdir(args.export_path)
print('[+] Mkdir export path:', args.export_path)
# cmd = "torch-model-archiver --model-name embedding --version 1.0 --serialized-file model.pt --extra-files MyHandler.py,faiss_index.bin,faiss_label.json --handler handler.py --requirements-file requirements.txt"
cmd = "torch-model-archiver "
cmd += "--model-name {} ".format(model_name_version)
cmd += "--version {} ".format(version)
cmd += "--serialized-file {} ".format(os.path.join(args.model_dir, args.model_file))
extra_files = [
args.handler_class,
os.path.join(args.model_dir, args.faiss_model_file),
os.path.join(args.model_dir, args.faiss_label_file)
]
cmd += "--extra-files {} ".format(",".join(extra_files))
cmd += "--handler {} ".format(args.handler)
cmd += "--export-path {} ".format(args.export_path)
cmd += "--requirements-file {} ".format(args.requirements)
cmd += "-f"
print(cmd)
os.system(cmd)
management_model_store(args.export_path, args.model_name, args.max_num_models)
if not os.path.isdir(args.config_path):
os.mkdir(args.config_path)
print('[+] Mkdir config path:', args.config_path)
config="""inference_address=http://0.0.0.0:{}
management_address=http://0.0.0.0:{}
metrics_address=http://0.0.0.0:{}
job_queue_size=100
install_py_dep_per_model=true
load_models=all""".format(args.pred_port, args.manage_port, args.metric_port)
config_file = os.path.join(args.config_path, "config.properties")
with open(config_file, "w") as f:
f.write(config)
def serving(args, version):
model_name_version = args.model_name+"_"+version
config.load_incluster_config()
k8s_apps_v1 = client.AppsV1Api()
template = client.V1PodTemplateSpec(
metadata=client.V1ObjectMeta(
labels={
"app":"torchserve",
"app.kubernetes.io/version":version
}
),
spec=client.V1PodSpec(
volumes=[
client.V1Volume(
name="persistent-storage",
persistent_volume_claim=client.V1PersistentVolumeClaimVolumeSource(
claim_name="serving-model-pvc"
)
)
],
containers=[
client.V1Container(
name="torchserve",
image="pytorch/torchserve:0.3.0-cpu",
args=["torchserve", "--start", "--model-store", "/home/model-server/shared/model-store/", "--ts-config", "/home/model-server/shared/config/config.properties"],
image_pull_policy="Always",
ports=[
client.V1ContainerPort(
name="ts",
container_port=args.pred_port
),
client.V1ContainerPort(
name="ts-management",
container_port=args.manage_port
),
client.V1ContainerPort(
name="ts-metrics",
container_port=args.metric_port
)
],
volume_mounts=[
client.V1VolumeMount(
name="persistent-storage",
mount_path="/home/model-server/shared/"
)
],
resources=client.V1ResourceRequirements(
limits={
"cpu":1,
"memory":"4Gi",
"nvidia.com/gpu": 0
},
requests={
"cpu":1,
"memory":"1Gi",
}
)
)
]
)
)
deployment = client.V1Deployment(
api_version="apps/v1",
kind="Deployment",
metadata=client.V1ObjectMeta(
name="torchserve",
labels={
"app":"torchserve",
"app.kubernetes.io/version":version
}
),
spec=client.V1DeploymentSpec(
replicas=2,
selector=client.V1LabelSelector(
match_labels={"app":"torchserve"}
),
strategy=client.V1DeploymentStrategy(
type="RollingUpdate",
rolling_update=client.V1RollingUpdateDeployment(
max_surge=1,
max_unavailable=1,
)
),
template=template
)
)
k8s_core_v1 = client.CoreV1Api()
service = client.V1Service(
api_version="v1",
kind="Service",
metadata=client.V1ObjectMeta(
name="torchserve",
labels={
"app":"torchserve"
}
),
spec=client.V1ServiceSpec(
type="LoadBalancer",
selector={"app":"torchserve"},
ports=[
client.V1ServicePort(
name="preds",
port=args.pred_port,
target_port="ts"
),
client.V1ServicePort(
name="mdl",
port=args.manage_port,
target_port="ts-management"
),
client.V1ServicePort(
name="metrics",
port=args.metric_port,
target_port="ts-metrics"
)
]
)
)
try:
k8s_apps_v1.create_namespaced_deployment(body=deployment, namespace=args.namespace)
print("[+] Deployment created")
except:
k8s_apps_v1.replace_namespaced_deployment(name="torchserve", namespace=args.namespace, body=deployment)
print("[+] Deployment replaced")
try:
k8s_core_v1.create_namespaced_service(body=service, namespace=args.namespace)
print("[+] Service created")
except:
print("[+] Service already created")
def main(args):
now = datetime.now()
version = now.strftime("%y%m%d_%H%M")
archive(args, version)
serving(args, version)
if __name__ == "__main__":
parser = argparse.ArgumentParser(description='')
parser.add_argument('--model_name', type=str, default="embedding")
parser.add_argument('--model_dir', type=str, default='/model')
parser.add_argument('--model_file', type=str, default='model.pt')
parser.add_argument('--faiss_model_file', type=str, default='faiss_index.bin')
parser.add_argument('--faiss_label_file', type=str, default='faiss_label.json')
parser.add_argument('--requirements', type=str, default='requirements.txt')
parser.add_argument('--handler_class', type=str, default="MyHandler.py")
parser.add_argument('--handler', type=str, default="handler.py")
parser.add_argument('--export_path', type=str, default='/deploy-model/model-store')
parser.add_argument('--config_path', type=str, default='/deploy-model/config')
parser.add_argument('--max_num_models', type=int, default=3)
parser.add_argument('--pred_port', type=int, default=8082)
parser.add_argument('--manage_port', type=int, default=8083)
parser.add_argument('--metric_port', type=int, default=8084)
parser.add_argument('--deploy_name', type=str, default="torchserve")
parser.add_argument('--svc_name', type=str, default="torchserve")
parser.add_argument('--namespace', type=str, default="default")
args = parser.parse_args()
main(args)
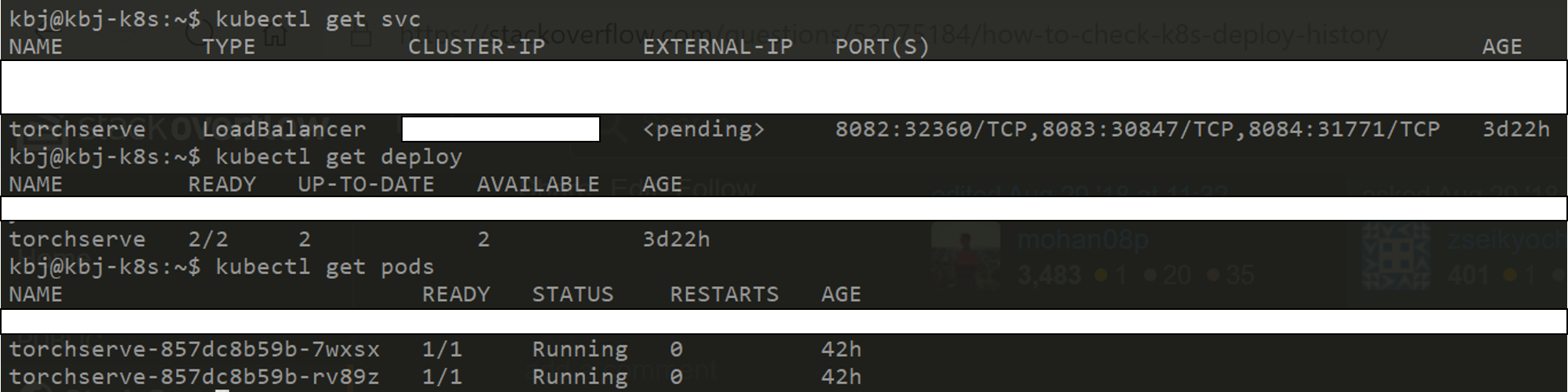
위는 service와 deployment 모두 정상 작동되는 모습이다. 다른 버전의 파이프라인을 한번 더 실행 시키면, 새로 학습된 모델을 load 하기 위해 deploy의 rolling update가 이루어지는 것을 확인 할 수 있다.
TorchServe에는 management_addres를 통해 이름이 동일한 모델을 새로 등록해서 버전관리가 이루어 지게 할 수 있다. 하지만 1. Rolling Update를 사용해보고 싶었고, 2. 다른 namespace job에서 torchserve 서비스로 접근을 허용하기 위해서는 부수적인 설정이 필요 했기 때문에 버전을 모델 이름에 포함시키고, 제한된 개수의 모델을 load 하는 방식을 선택하였다. 추후 A/B Test를 구현할 때에는 모델을 버전으로 관리하는 방법을 포함해서 포스팅하려고 한다.
Use API
이제 서비스 address로 여러가지 요청을 보낼 수 있다. management api는 url에서 확인 가능하다. 또한 inference api는 url에서 확인 가능하다.

management_addres를 통해 등록된 model 리스트 확인
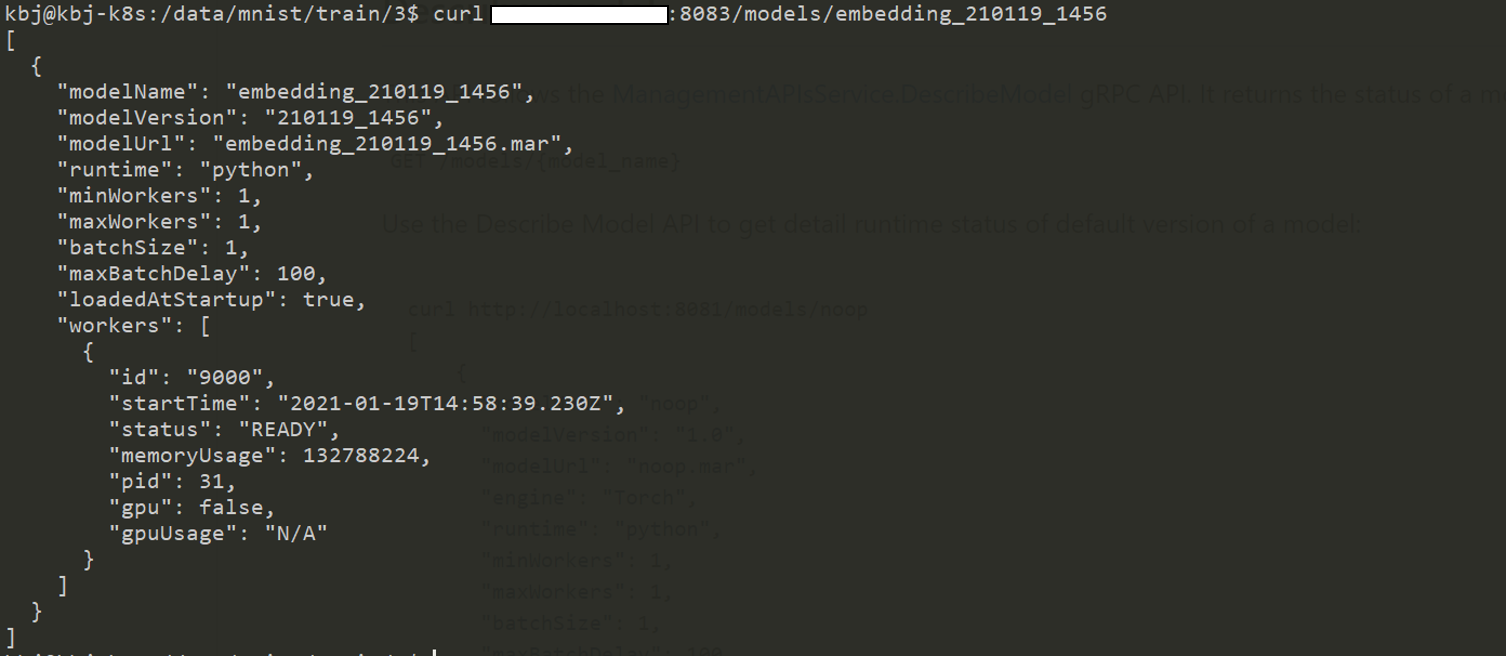
management_addres를 통해 등록된 model의 세부사항 확인

inference_address를 통해 inference.
- dists: 가장 가까운 embedding과의 거리
- pred: 가장 가까운 embedding의 label
다음 포스팅에는 deploy된 api를 slack을 Trigger로 활용해 관리하는 방법에 대해 소개한다.