| 2018 CVPR에서 Oral로 발표된 논문이다. (Arxiv | Code) |
Introduction
기존 object detection 모델들을 보면 각 proposal에 object classification과 bounding box regression이 개별적으로 이루어 졌다. 또한 non-maximum suprression (NMS)도 heuristic하게 post-processing step에서 시행되었다.
저자는 딥러닝이 유행하기 이전의 object relation을 이용하여 이 문제를 해결하고자 하였다. 그러나 보통 object는 각기 다른 위치, 다른 크기, 다른 종류 그리고 다른 이미지로 검출 되기 때문에 object-object relation 모델을 만드는 것은 어렵다. 이때 저자는 NLP에서 성공을 얻은 attention model (Attention is all you need)에 영감을 받았다고 한다. 각기 다른 위치, 특징에 상관 없이 모든 elements 사이의 dependency를 모델화 시킬 수 있기 때문이다.
본 논문에서 original weight와 geometric weight를 이용한 attention module을 제안한다. 기존 방식에 geometric weight를 추가로 사용한 이유는 object간의 상대적인 공간의 관계를 파악하기 위해서 라고 한다. 이 module은 object relation module 이라 한다.
Method
Object Relation Module
기본 “Scaled Dot-Product Attention”의 과정을 기반으로 설계 되었다. Scaled Dot-Product Attention을 간략하게 설명하면, 쿼리 q와 key K의 요소간의 유사도를 계산하여 value V의 값을 변화 시키는 메커니즘이다. 계산된 유사도에 따라 V에 영향을 끼치는 정도가 달라지며, 이를 attention이라 생각하면 된다. V는 결국 관련 있는 요소들에 영향을 받아 값이 변한다.
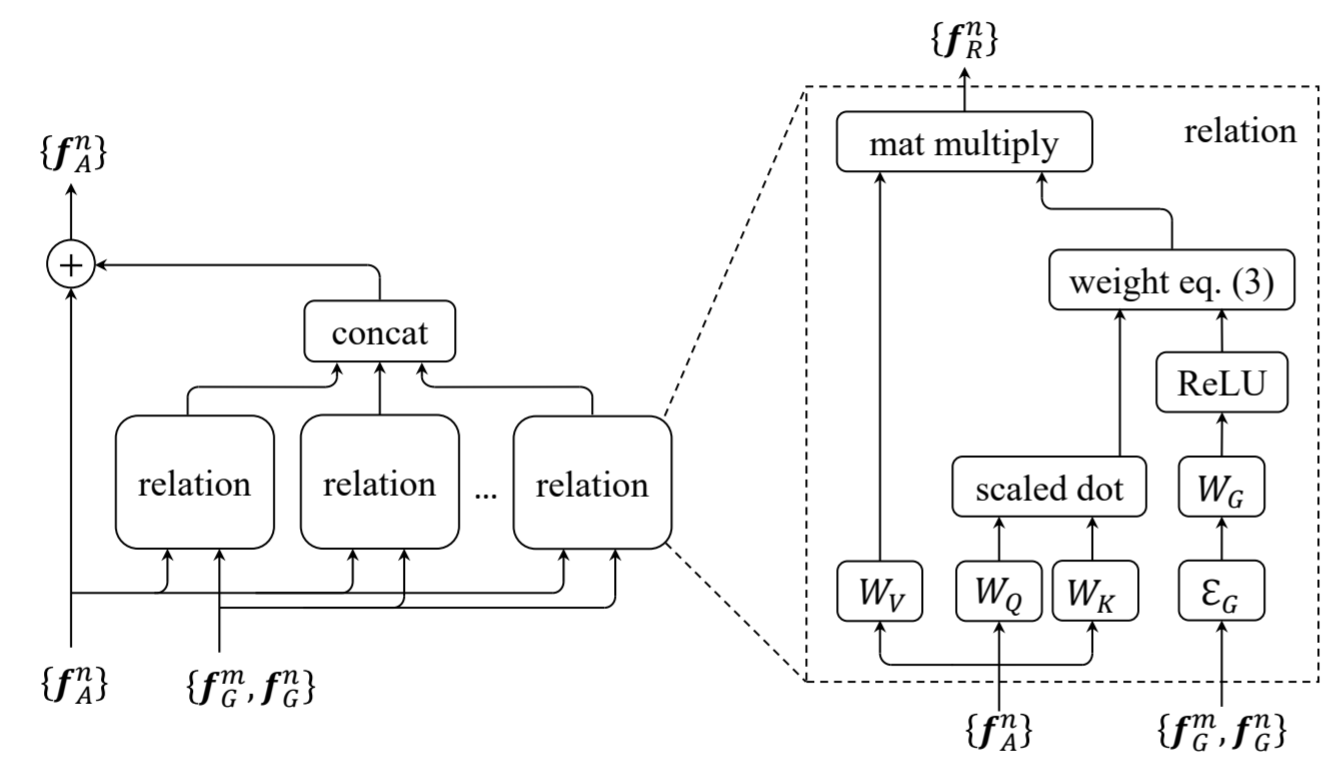
이제 object relation module에 대한 설명을 하겠다. 우선 각 object는 geometric feature(f_G)와 appearance feature(f_A)로 이루어져 있다. 당연히 geometric feature은 4-d 이며, appearance feature은 architecture 구조에 따라 달라진다.
논문에서는 top-down 방식으로 수식을 설명했지만 원활한 설명을 위해 down-top 방식으로 설명하겠다.
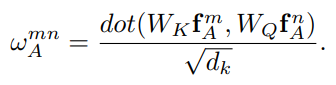
위는 m object와 n object의 appearance feature를 이용하여 appearance weight를 Scaled Dot-product로 구하는 식이다. 각 appearance feature은 같은 공간으로 임베딩 되어 유사도가 계산된다. 그리고 유사도로 weight가 결정된다. 이 weight의 softmax 값을 이용하면 일반적인 attention 모델이 되지만, 아까 말했듯이 한가지의 weight를 더 고려하였다.
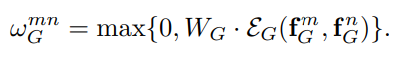
위는 m object와 n object의 geometry feature를 이용하여 geometry weight를 구하는 식이다. 우선 각 geometry feature은 높은 차원으로 임베딩된다 (위 식의 EG). translation invariant, scale transformation 등을 위해 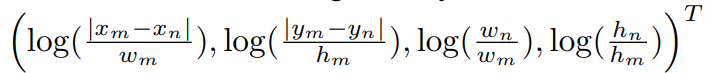 로 바꾸어 계산한다. 그 후 Attention is all you need 에서 소개한 Positional Encoding을 이용하여 d_g 차원으로 임베딩 된다. 그 후 WG를 이용하여 scalar weight가 되고, ReLU function을 이용한다. ReLU를 거치는 이유는, 두 object 간의 geometric 관계이기 때문이다.
로 바꾸어 계산한다. 그 후 Attention is all you need 에서 소개한 Positional Encoding을 이용하여 d_g 차원으로 임베딩 된다. 그 후 WG를 이용하여 scalar weight가 되고, ReLU function을 이용한다. ReLU를 거치는 이유는, 두 object 간의 geometric 관계이기 때문이다.
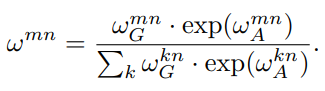
이로서 object m과 n의 attention weight(relation weight)를 구할 수 있게 된다. 기존 attention 식과 달리 geometric weight이 추가되었다. 이 relation weight은 다른 object로 부터 받는 영향을 뜻한다. 식을 보면 전체 object 중 m이 n에게 미치는 영향을 확률 값으로 나타낼 수 있게 되었고,
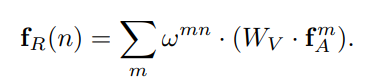
위 식을 이용하여 모든 object 간의 weight sum을 한다. 이를 통해 다른 object의 영향이 첨가된 relation feature를 얻을 수 있다.
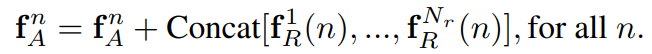
object relation module은 총 N_r개의 relation feature을 이용하였다. 즉 multi-head attention과 같이 다양한 relation feature들을 concat 하였다. 인풋과 아웃풋의 dimension을 맞추기 위해 각 relation feature의 dimension은 appearance feature의 1/N_r 로 정하였다.
각 object의 appearance feature의 차원을 d_f, key의 차원을 d_k로 두면, 파라미터 공간의 크기가 계산이된다.
- W_K: d_k x d_f (d_f 차원(object m)을 d_k 차원으로 임베딩)
- W_Q: d_k x d_f (d_f 차원(object n)을 d_k 차원으로 임베딩)
- W_G: d_g (임베딩된 d_g차원을 scalar weight로 바꿈)
- W_V: d_f x d_f/N_r (d_f 차원(object m)을 d_f/N_r(relation features))
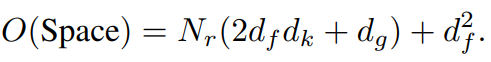
따라서 총 N_r 개의 relation feature을 만들기 때문에 위 식이 성립된다. 본 논문에서는 N_r = 16, d_k = 64, d_g = 64 로 놓았고, N과 d_f는 수백으로 놓았다.
위 까지 포스팅을 쓰다보니.. 얼른 수식을 쓸 수 있게 블로그 손봐야겠다..
Relation Networks
대게의 object detection 모델은 총 4개의 단계로 이루어진다.
- 전체 이미지 feature map 생성
- 주로 ImageNet으로 pre-trained된 backbone 네트워크를 사용하고, detection task로 fine-tuned 된다.
- regional feature 생성
- 이미지 전체 feature map으로 부터 object가 있을 만한 region을 추천하고, RoI pooling layer로 각 지역의 feature 고정된 크기로 만든다.
- instance recognition
- 각 regional feature에 regression을 이용하여 지역의 object category 가능성을 예측하고, bounding box를 refine 한다.
- duplicate removal
- 주로 post-processing에서 이루어지며, non-maximum suppression(NMS)를 이용한다. 이 단계로 인해 end-to-end가 불가능해진다.

앞서 말한 object relation module은 뒤의 두 단계(instance recognition, duplicate removal)에 적용이 된다. 그리고 이를 통해 first end-to-end general object detection system이 된다. 그리고 위 단계를 보면 알 수 있듯이 object relation module은 Faster RCNN, FPN과 같이 RPN을 쓰는 two-stage object detection에 적용된다. object relation module을 보면 object 지역의 추천이 우선 되어야하고, 각 지역의 feature 크기가 동일하기 때문이다.
Relation for Instance Recognition
RoI pool layer을 통과한 feature은 2개의 fc layer을 거친 후 linear layer을 통해 score와 bounding box를 예측된다. object relation module은 fc layer 후에 놓여진다. 이를 통해 instance recognition이 강화된다고 한다. 또한 일반적인 instance recognition은 각 지역에 FC layer을 붙이지만, 논문의 모델은 추천받은 N개의 지역을 한꺼번에 이용한다.
Relation for Duplicate Removal
heuristic한 NMS 보다 간단하고 효과적인 remove duplicate를 제안한다. 이 또한 relation module를 사용한다. duplicate removal은 ground truth object 마다 correct/duplicate bounding box인지 분류하는 문제이다.
본 논문에서는 이 분류 문제를 네트워크를 통해 해결한다. 검출된 object의 집합이 인풋이며, 각 object는 1024-d feature, classification score(s0), 그리고 bounding box를 갖고 있다. 네트워크를 통해 아웃풋으로 얻어진 확률 s1을 s0와 곱해 최종 classification score을 얻는다. 즉 좋은 검출일 수록 높은 classification score이 얻어진다. 네트워크는 총 세단계로 구성되어있다. 이때 relation module을 썼기 때문에 전체 정보를 한꺼번에 사용할 수 있고, 효과적인 end-to-end learning이 가능하다.
- 1024-d feature와 classification score(s0)를 이용해서 새로운 appearance feature을 생성한다.
- relation module을 이용하여 전체 object의 appearance feature을 transform 한다.
- linear classifier와 sigmoid를 통해 [0, 1]의 확률 값을 얻는다.
Rank Feature classification score(s0)의 값 그대로 사용하지 않고, rank로 변환하여 사용하였다. 그리고 위에서 언급한 Attention is all you need의 positional encoding을 통해 128-d로 임베딩 된다. 128-d rank 벡터와, 1024-d feature는 각각 128-d로 임베딩 된 후 더해져서 relation module의 인풋으로 사용된다.
대게 학습할때와 평가할때 같은 threshold를 주어야 좋은 성능이 나온다. 예를 들어 threshold가 0.5로 학습 될때 mAP@0.5의 성능이 가장 높을테고, mAP@0.75의 성능은 제일 높지 않을 것이다. 하지만 이 방법을 사용하면 사전 파라미터 세팅 없이 적절한 학습이 가능하다. threshold를 0.5, 0.6, 0.7, 0.8, 0.9로 다양하게 두어 각기 다른 W_s를 학습하였다. inference 때에는 확률 값들의 평균을 output으로 하였다.
학습할 때를 보면 대부분의 검출은 duplicate이고, crrrect인 검출은 1퍼센트가 채 되지 않는다. 이런 불균형에도 불구하고 단순한 cross entropy loss로 학습을 진행 했다고 한다. 왜냐하면, 대부분의 검출이 매우 작은 score(s0)을 가지고 있고, s0와 s1를 곱했기 때문에 더 작은 score 값을 가진다. 이것들은 역전파 시 정말 미미한 영향 밖에 미치지 않는다. 반면에, 큰 score(s0)를 가진 몇 개 없는 duplicate 검출에 포커스를 맞추어 학습이 진행되게 된다. focal loss와 비슷한 의미를 가진다고 생각하면 된다.
End-to-End Object Detection
본 모델은 세가지 loss를 사용한다.
- region proposal loss
- instance recognition loss
- duplicate classification loss
각 loss는 동일한 가중치가 주어진다. 하지만 잘 생각해보면 instance recognition step과 duplicate removal step은 대조적인 느낌이 있다. instance recognition은 모든 object가 같은 ground truth에 근접하도록 학습이 진행 될 것이고, duplicate removal은 한 ground truth에 한 object만 매칭 되도록 학습이 되어진다. 하지만 실험적으로 봤을 때 잘 수렴이 되고, s0와 s1를 곱하는 식을 통해 충돌이 일어나지 않는 것을 확인하였다. instance recognition은 좋은 검출을 위한 높은 s0 점수를 내는 것만 신경을 쓰고, duplicate removal은 duplicate를 분류하기 위해 낮은 s1 점수를 내는 것에 신경을 쓴다. 한가지 더 생각해야하는 점은 duplicate removal step은 instance recognition step의 결과를 이용해서 이루어지기 때문에 의존적이지 않냐? 이다. 하지만, 실험적으로 전혀 문제되는 것이 없었다. duplicate removal step 학습이 상대적으로 더 쉽고, 불안정한 label은 정규화 효과를 낼 수 있기 때문이다.
Experiments
모든 실험은 80 object categories를 가지는 COCO detection dataset으로 시행되었다. backbone 네트워크로는 ResNet-50, ResNet-101을 사용하였다.
Relation for Instance Recognition
Instance Recognition에 대한 실험을 하기 위해 Duplicate Removal에 NMS 방법을 사용하였고, IoU threshold를 0.6으로 두었다.

일반적인 2fc 방법을 baseline으로 두었다. 이는 29.6 mAP를 기록하였다. 세가지 파라미터를 바꿔가며 실험을 하였다. 우선 geometric feature에 대한 파라미터이다. 위 표를 보면, geometric feature을 사용하지 않을 때(none), geometric feature을 appearance feature에 더한 후 Relation Module의 feature을 사용한 경우(unary), 위에서 제안한 방법(ours) 중 ours가 가장 높은 성능(31.9 mAP)를 기록하였다. 두번째로 relation의 개수가 16일 때 가장 높은 성능을 기록하였다. 마지막으로 Relation Module을 더 많이 이어 붙였을 때(더 많은 파라미터 사용) 더 높은 성능을 기록하였다. 이는 첨부하지 않은 표를 보면 알 수 있는데, 파라미터를 많이 사용할 수록 더 좋은 성능을 기록할 수 있다고 한다.
Relation for Duplicate Removal

Duplicate Removal에 대한 실험을 하기 위해 2fc를 이용한 Faster RCNN의 방법을 baseline으로 사용하였다. rank feature을 사용하지 않을 경우 26.6 mAP, s0 그대로 일반적인 임베딩을 통해 사용한 경우 28.3 mAP의 성능 하락이 있었다. 그리고, 다른 파라미터 또한 제안한 방법이 가장 좋은 성능을 낼 수 있었다.
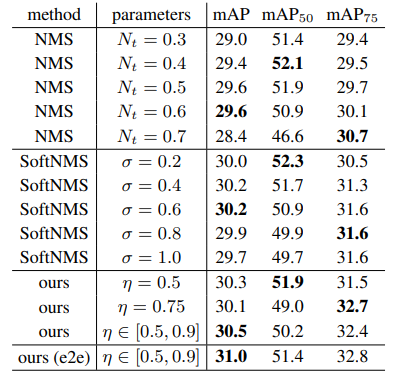
NMS 그리고 softNMS와 비교를 하였다. 당연히 IoU 파라미터 혹은 normalizing 파라미터를 바꿀 때마다 각 metric의 정확도가 제각각 이었다. 하지만 논문에서 제안한 방법을 이용하면, 파라미터가 각각 0.5일때 mAP50, 0.75일때 mAP75의 성능이 가장 좋았고, [0.5, 0.9]를 사용한 경우 일반적인 mAP에 좋은 성능을 얻을 수 있었다. 즉 clear 하다고 한다. 또한 end-to-end 방법을 사용한 경우 NMS, softNMS와 비교했을 때, mAP에 가장 좋은 성능을 얻었다.
End-to-End Object Detection

위 표를 보면 baseline->RM for instance recognition->RM for instance recognition, duplicate removal 순서로 성능향상이 이루어 지는 것을 알 수 있다. 그리고 표에서 알 수 있듯이 이 방법은 faster RCNN, FPN, 그리고 DCN 모두에 적용된다고 한다.
Review
근래 들어 가장 읽히지 않은 논문이었던 것 같다.. 각 방법의 사용법이나 성능에 대해서는 잘 나와있지만, “왜 이 방법을 쓰면 기존에 비해 좋아지는지”에 대한 설명이 실험적으로 밖에 보여지지 않아서 아쉬웠던 것 같다.