Pre-training과 Data Augmentation, 그리고 Self-training에 대한 실험에 관한 논문 (Paper)
Object Detection 뿐만 아니라 여러 Vision Task에서 ImageNet으로 학습된 Pre-train은 필수로 사용된다. 하지만 Rethinking ImageNet PreTraining 에서 이에 반대 되는 입장을 내었다. 저 논문에서는 Pre-Training은 빠른 학습을 돕긴 하지만 Scratch(w/o Pre-Training)로 학습을 해도 충분히 좋은 성능을 낼 수 있다고 여러 실험을 통해 증명하였다.
본 논문에서는 다시한번 Pre-training의 필요성을 부정하며, 오히려 Self-training을 하면 더 좋은 성능을 낼 수 있음을 강조한다. 또한, 강력한 Data Augmentation을 이용할 경우 오히려 Pre-training이 성능을 악화 시킨다고 실험을 통해 밝혔다.
Data Augmentation
본 논문에서는 Data Augmentation을 네단계로 나누어 실험하였다.
- Augment-S1
- 가장 약한 Augmentation, Flip과 Crop으로만 구성
- Augment-S2
- 두번째로 약한 Augmentation, Augment-S1에 AutoAugment 추가
- Augment-S3
- 두번째로 강한 Augmentation, Augment-S2에 Large Scale Jittering을 추가
- Augment-S4
- 가장 강한 Augmentation, Large Scale Jittering과 RandAugment 그리고 Flip, Crop으로 구성
Pre-training
세가지의 weight을 사용하여 실험하였다.
- Rand Init
- pre-train 없이 랜덤으로 초기화된 weights 사용
- ImageNet Init
- ImageNet으로 학습된 weights 사용(84.5% top-1 accuracy)
- ImageNet++ Init
- Noisy Student 방법으로 학습된 weights 사용(86.9% top-1 accuracy)
Self-training
Noisy Student 방법으로 학습을 진행하였다.
- Teacher model
- label된 COCO dataset으로 학습
- unlabeld ImageNet dataset을 통해 pseudo label 생성
- Student model
- label된 COCO dataset과 pseudo label된 ImageNet dataset으로 학습
Experiments
Pre-training - Augmentation, Labeled dataset size
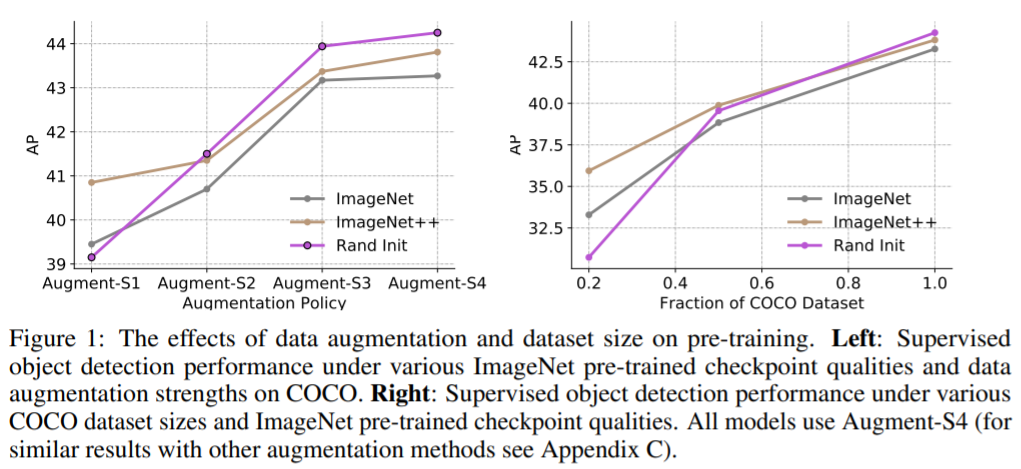
첫번째로 Data Augmentation과 dataset size에 따른 pre-training 기법의 성능에 관한 실험이다.
우선 Data Augmentation의 세기가 강할 수록 pre-training 기법의 성능보다 init weight의 성능이 높다. 위 figure의 좌측 그래프를 보면, pre-training 기법을 사용한 모델(ImageNet, ImageNet++)의 경우 랜덤 init weight을 사용했을 때 보다 Augment-S2, 3, 4에서 낮은 성능을 기록하였다.
또한 Labeled dataset이 많을 수록 오히려 Rand Init의 성능이 Pre-training 기법 보다 더 좋아지는 것으로 확인하였다.
pre-train 때 사용한 데이터(ImageNet)와 fine-tune 데이터(COCO)의 corpus가 달라서 생긴 성능 저하가 아닐까? Data augmentation을 더 세게 적용하거나, labeled dataset의 수가 많아질 수록 두 데이터의 차이가 더 심해진 것 같다. 둘다 생활 속의 이미지라 하지만, 다른 데이터 이미지의 feature을 잘 뽑아내는 모델로 학습을 전개하는데에는 한계가 있을 것 같다. 반면 scratch로 진행한 학습인 경우, 애시당초 coco dataset에 집중해서 더 좋은 성능을 낼 수 있지 않았을까…
Self-training - Augmentation, Labeled dataset size
이번에는 Self-training 기법과 Pre-training 기법을 비교하는 실험을 보였다. 위와 마찬가지로 Augmentation의 세기, Labeled dataset 수의 변화로 두 기법의 성능 차이를 보였다.

위 표를 보면, Augmentation 세기가 강해질 수록 Pre-training 기법(ImageNet Init)의 성능이 Rand Init 보다 낮아지는 반면, Self-training에 경우 Rand Init 보다 높은 성능을 기록하였다. 따라서 강한 Augmentation인 경우, Rand Init + Self-training 기법이 좋은 선택이다.
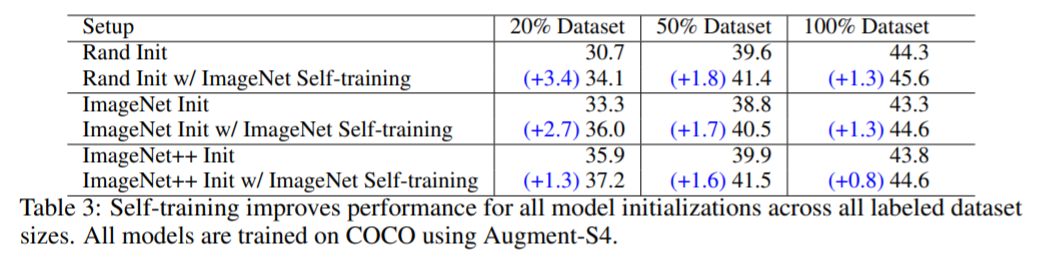
또한 데이터셋의 개수가 많아지면, Self-training 기법을 선택해야 Rand Init 보다 높은 성능을 기록할 수 있었다. 신기한 점이 위 figure 1에서는 Rand Init 보다 작은 성능의 pre-training 기법 모델도, Self-training을 적용하면 더 높은 성능을 기록한다.
위에서 느낀 Dataset 차이를 Self-training으로 보완, 강화 시킨 것이 아닐까? Self-training으로 ImageNet과 COCO dataset 모두에 좋은 성능을 내는 모델로 학습 되는 것이 아닐까?
Self-supervised Pre-training
Pre-training에는 Self-supervised Pre-training 기법이 있다. 이번 실험에는 Self-supervised Pre-training 기법 중 SimCLR 기법을 이용하였다. SimCLR은 최근에 SOTA를 기록한 self-supervised Pre-training 기법으로 SimCLR에서 확인할 수 있다.
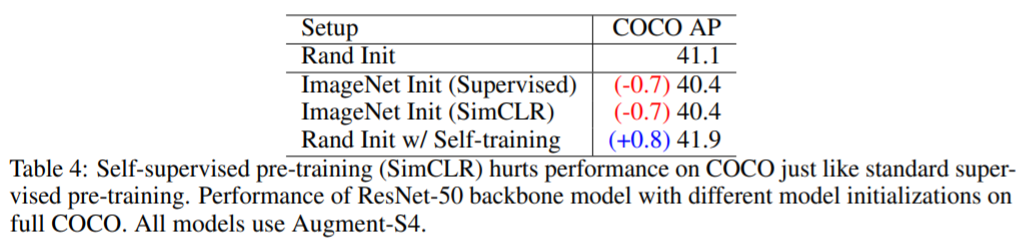
위 표는 Augment-S4와 full COCO dataset을 사용한 실험 결과이다. 하지만 SimCLR 기법을 사용했음에도 불구하고 똑같은 결과가 나왔다.
따라서 Self-training 기법이 어떤 Pre-training 기법 보다 좋은 성능을 기록하였다.
Discussion
Rethinking pre-training and universal feature representations
Our intuition for the weak performance of pre-training is that pre-training is not aware of the task of interest and can fail to adapt.
저자는 pre-training weights이 새로운 task(e.g., Object Detection)에 적응하지 못해서 생긴 결과라고 소개한다. 예를들어 ImageNet에서의 좋은 feature는 COCO에서 필요한 positional information(위치 정보)을 갖고 있지 않다. 따라서 Self-training을 통해 새로운 task에 적응 하는 것이다.
Joint-training
ImageNet과 COCO의 mismatch를 해결하기위해 Joint-training을 적용해보았다. Joint-training이란 여러개의 Loss를 더하여 학습하는 것을 뜻한다. 즉 ImageNet classification과 COCO Object detection을 함께 학습해서 실험해보았다. 논문에서의 결과를 요약하자면, 이 또한 Rand Init 그리고 Pre-training 기법 보다 향상된 성능을 보였지만, Self-training 보다는 낮은 성능을 기록하였다. 하지만, Self-training과 Joint-training을 함께 적용 해보았더니 가장 좋은 성능을 냈다.
Limitations
하지만 물론 Pre-training 모델을 사용하면 PASCAL과 같은 적은 데이터셋에 빠르게 좋은 성능을 낼 수 있다. 반면 Self-training 기법은 아무래도 학습하는 시간이 오래 걸릴 수 밖에 없다.
Review
모델만 설명하는 논문보다 이러한 기존 틀을 깨는 실험적인 논문이 더 재밌는 것 같다. 실험을 하나하나 읽으면서 많은 생각을 하게 되었고, 그 생각의 일부분이 Discussion에 쓰여있는 것을 보았을 때의 쾌감은 말로 표현 못할 것 같다.