Paper
논문 리뷰 - Self-training with Noisy Student improves ImageNet classification
2019년 11월, ImageNet 데이터셋에 대해 State-of-the-art를 갱신한 논문이다. (Arxiv)
Introduction
Image recognition(classification) 분야는 AlexNet, VGG, ResNet 부터 시작해서 NASNet 최근에는 EfficientNet 등 많은 연구가 진행되며 발전해왔다. 이 모델들은 supervised learning으로 큰 labeled images를 필요로 한다. 하지만 unlabeled images를 이용하지는 않았다. 이 논문은 ImageNet에 속하지 않은 unlabeled images 까지 이용하여 ImageNet 정확성의 SOTA를 갱신하며, robustness 성능 까지 높이는 방법에 대해 설명한다.
self-training framework를 사용하며, 총 세 가지 단계로 이루어져 있다.
- labeled images로 teacher model 학습
- teacher model을 이용하여 unlabeled images에 대한 pseudo labels 생성
- labeled images와 pseudo labeled images를 이용하여 student model 학습
이후 student model을 다시 teacher model로 두어 새로운 student model 학습 반복한다. student model를 학습 할 때 input image와 model에 noise를 주어 학습을 진행하며, 이를 통해 ensemble과 비슷한 효과를 낸다.
정리해서 모델을 요약하자면,
본인보다 똑똑한(equal-or-larger student model) 학생들(with noise)에게 본인도 확실하지 않은 어려운 공부(pseudo labeled images)와 확실한 공부(labeled images)를 시킨다. 학생들은 머리를 맞대며(ensemble 같은 효과) 청출어람 하고, 선생님이 되어 새로운 학생을 같은 방식으로 가르친다.
Method
Self-training with Nosiy Student

우선 labeled images와 cross entropy loss를 통해 teacher model을 학습한다. 그 후 학습된 teacher model을 이용하여 unlabeled images의 pseudo labels를 생성한다.
이때 pseudo labels은 soft하거나 hard하다. label이 soft하다는 뜻은 continuous distribution 한 label을 뜻한다. softmax를 거쳐 나온 output을 보면 이해가 쉽다. 각 클래스로 예측될 확률 값이 들어있다. 이는 “이 사진은 사자일 확률이 가장 높은데 고양이랑도 닮았네”와 같은 knowledge로써 사용 가능하다. hard한 label은 one-hot vector을 생각하면된다.
이렇게 생겨난 pseudo labeled images, labeled images와 cross entropy loss를 이용하여 noise가 추가된 student model을 학습한다.
마지막으로 학습된 student model을 teacher model로 두어 새로운 pseudo labels를 생성 후, 새로운 student model을 학습하는 과정을 반복한다.
다른 self-training, semi-supervised learning 모델과 차이로는
- student model에 noise 추가
- teacher model과 비슷한 크기를 가지는 student model
이 있다. 특히 Knowledge Distillation은 student가 teacher 보다 빠르게 동작할 수 있도록 학습되어 지기 때문에 본 논문의 모델과는 차이가 있다고 한다. 저자는 이 논문이 Knowledge Expansion으로 student에 더 큰 caoacity을 제공하고 어려운 환경(noise) 속에서 학습을 시켜, 학생이 선생님 보다 더 뛰어나게 만드는 모델이라고 한다.
Noising Student
앞서 말한 noise는 총 세 가지 이다.
- input noise
- RandAugment (data augmentation): 자동 data augmentation
- model noise
- dropout: 확률적으로 특정 뉴런을 학습에 참여 x
- stochastic depth: 학습시 무작위로 layer 생략(skip connection 사용) -> 짧은 network로 학습 후 deep network로 테스트
RandAugment을 통해 바뀐 이미지가 기존 이미지와 같은 label인 사실을 student가 알게된다. 이를 통해 더 어려운 이미지도 예측을 잘 할 수 있게 된다. dropout과 stochastic depth인 경우 ensemble과 같은 효과를 내게한다. 다시말하면 강력한 ensemble 효과를 흉내 낸다고 한다.
Other Techniques
data filtering: teacher model이 낮은 confidence로 예측하는 이미지는 대부분이 out-of-domain images 이기 때문에 filter 하였다.
balancing: ImgaeNet 데이터를 보면 각 class 마다 비슷한 개수의 labeled images가 있지만, unlabeled images에 대해서도 각 class 마다 이미지 개수의 balance를 맞춰줘야한다. 적은 데이터 개수의 class 이미지를 duplicate하여 늘렸고, 매우 많은 데이터 개수의 class 이미지 중 높은 confidence를 보이는 이미지만 사용한다.
pseudo labels: 위에서 언급했듯이 soft/hard labels 중 soft pseudo labels를 사용했을 때 out of domain unlabeled data에 대해 성능이 조금 더 좋다. 따라서 soft pseudo labels를 사용하여 실험하였다.
Experiments
Details
- dataset
- labeled dataset: ImageNet 2012 ILSVRC challenge
- unlabeled dataset: JFT 300M (data filtering과 balancing 적용)
* ImageNet으로 학습된 EfficientNet-B0를 이용
- confidence score > 0.3
- class 마다 130K images filter
- 130K images 보다 적을 시 duplicate randomly
- 결국 130M images로 student model 학습
- Architecture
- EfficientNets
* EfficientNet-B7
- EfficientNet-L2
- EfficientNets
* EfficientNet-B7
- Training
- 큰 batch size 사용
- fixing the train-test resolution discrepancy
* 350 epoch 동안 작은 resolution 사용
- 그 후 1.5 epoch 동안 unaugmented labeled images에 대해 큰 resolution으로 fine-tuning
- fine-tuning시에 shallow layer freeze
- Noise
- stochastic depth: final layer에 0.8을 두고 다른 layer은 linear decay rule을 따르도록 한다.
- dropout: final classification layer에 0.5
- RandAugment: magnitude=27
- Iterative training
- 3 iterations
- 1st teacher model: EfficientNet-B7
- 1st student model: EfficientNet-L2
- 2nd student model: EfficientNet-L2
- 3rd student model: EfficientNet-L2
- batch size의 ratio (unlabeled batch size : labeled batch size)를 크게 두었다.
* 1st student model -> 14:1
- 2nd student model -> 14:1
- 3rd student model -> 28:1
ImageNet Results
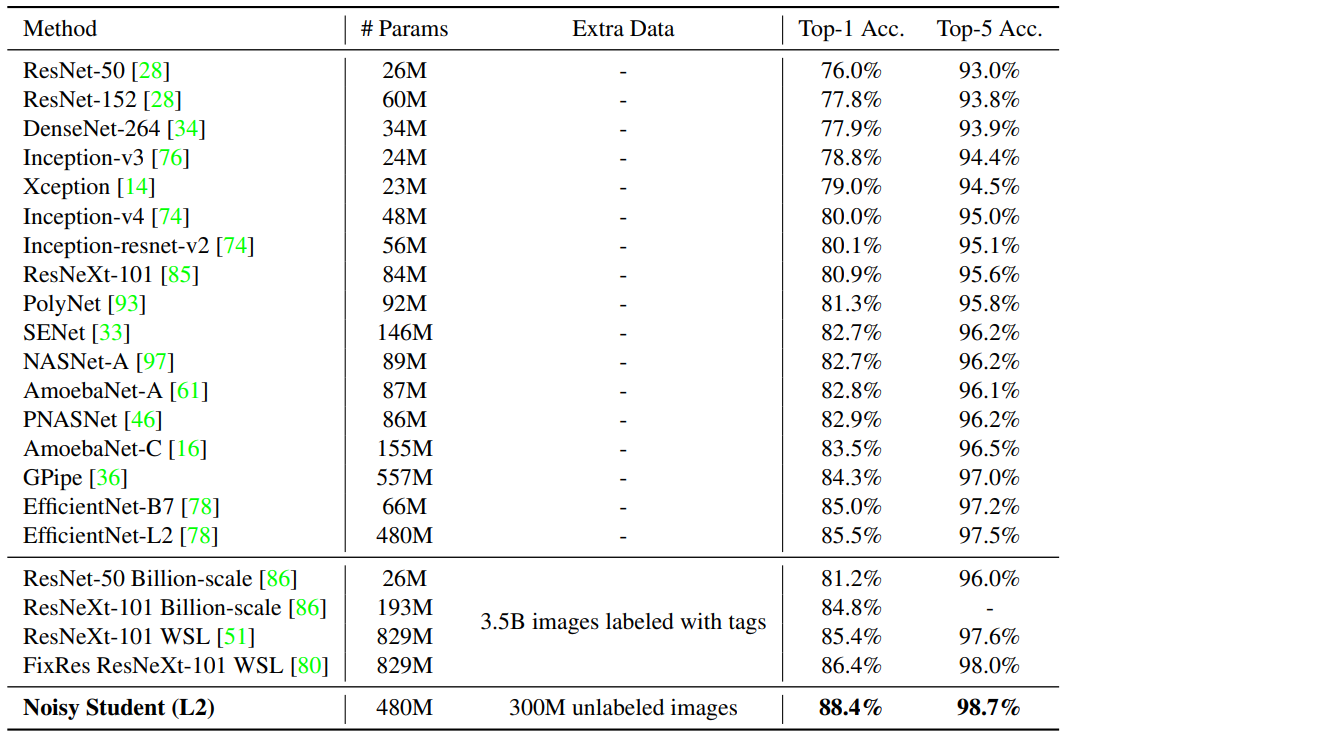
위 표는 ImageNet 2012 ILSVRC validation set accuracy이다. 이 논문에서 소개한 Noisy Student(EfficientNet-L2)가 88.4% top-1 accuracy로 SOTA를 갱신하였다. 기존 EfficientNet-B7에 비해 3.4% 성능 개선을 하였다. 마찬가지로 같은 구조인 EfficientNet-L2에서 Noisy Student 방법의 추가로 2.9% 성능 개선을 하였다. 또한 tag로 labeling 된 Billion Instagram images를 사용한 SOTA 모델(FixRes ResNeXt-101 WSL)과 비교해보면, 오직 300M의 unlabeled image을 사용하여 더 높은 성능을 기록하였고 parameter의 개수 또한 1/2 차이 난다.
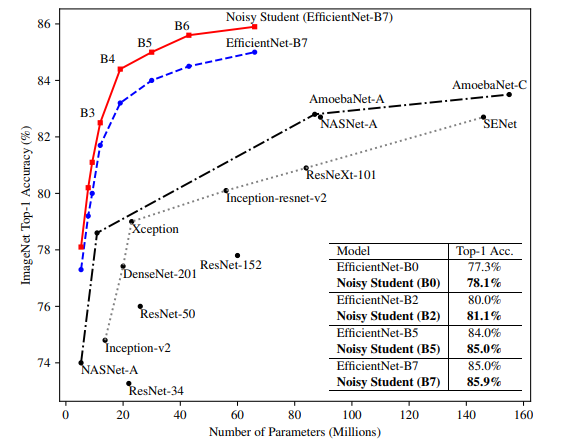
위 그래프는 Noisy Student가 기존 EfficientNet에 비해 효과가 있는지를 알아보기 위해, iterative training을 진행하지 않고 딱 한번의 student 학습을 진행하였을때의 성능을 나타낸 그래프이다. 이때 teacher와 student는 같은 모델로 학습하였다. EfficientNet-B0 부터 EfficientNet-B7 까지 모델의 크기를 다양하게 변화 시켰다. 또한 공정성을 위해 기존 baseline의 EfficientNet에 RandAugment를 적용 시켰다. 모든 모델 사이즈에 있어 약 0.8%의 성능이 향상되었고, 다른 모델들과 비교했을 때 파라미터 개수에 비해 성능이 월등히 높다. 그리고 또한 iterative training 없이도 어느정도 성과가 있는 것으로 확인됐다고 한다.
Robustness Results
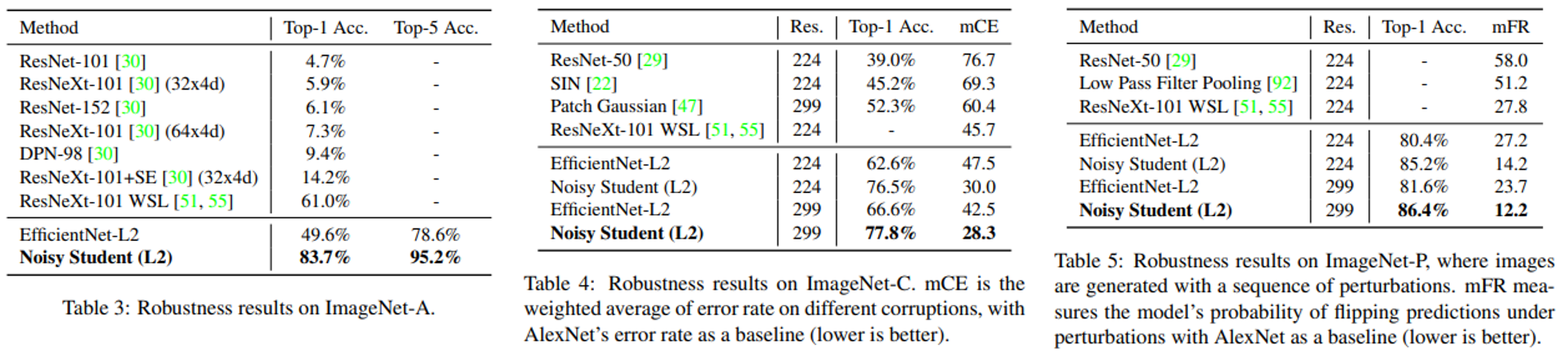

Robustness 측정을 위해 ImageNet-A, ImageNet-C, ImageNet-P을 이용하였다. ImageNet-A 데이터셋은 SOTA model들이 공통적으로 어려워하는 이미지들을 모은 데이터셋이다. ImageNet-C와 ImageNet-P 데이터셋은 blurring, fogging, rotation, 그리고 scaling 등과 같은 이미지에 흔히 발생할 수 있는 Corruption과 perturbation이 적용된 데이터셋이다. 이러한 이미지들은 어려운 task(ImageNet-A)이며, 트레이닝 데이터와 다르기(ImageNet-C, ImageNet-P) 때문에 robustness를 측정하는데에 사용된다.
- ImageNet-A
- 200 classes의 이미지로 top-1 과 top-5 accuracy를 측정
- ImageNet-C
- 15가지 corruption으로 실험
- 각 corruption 마다 5 noise level
- mCE(mean corruption error)
- AlexNet의 error rate를 baseline
- 15가지 corruption error rate의 평균
- AlexNet과 비교했을때 image noise에 얼마나 강한 모델인가
- ImageNet-P
- mFR(mean flip rate)
- 다른 perturbations 마다 flip probability의 평균
- flip probability: perturbation이 바뀔 때 top-1 prediction이 바뀔 확률
- AlexNet의 flip probability를 baseline
- mFR(mean flip rate)
- 다른 perturbations 마다 flip probability의 평균
위 표를 보면 알 수 있듯이 ImageNet-A의 top-1 accuracy를 61.0%로 부터 83.7% 까지 올렸다. ImageNet-C의 경우 mCE(mean corruption error)를 45.7 에서 28.3 까지 낮추었으며, ImageNet-P의 경우 mFR(mean flip rate)를 resolution에 따라 14.2와 12.2까지 낮추었다. 저자는 이 논문이 robustness 향상을 의도 하지 않았기 때문에 이러한 결과가 놀랍다고 한다.
Adversarial Robustness Results
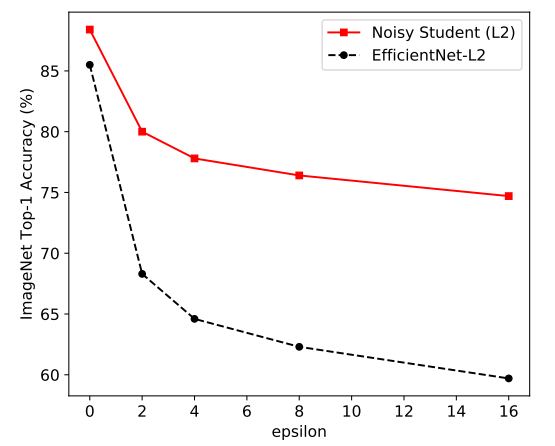
이번에는 Adversarial attack의 일종인 FGSM(Fast Gradient Sign Method)을 적용하였다. 이 실험에서도 저자는 이 모델이 Adversarial Robustness를 고려하지 않고 만들었지만 좋은 성능을 내는 것에 놀라워한다. 그래프를 보면 epsilon이 증가할 수록 더욱 큰 차이의 성능 개선을 하는 것을 알 수 있다.
Discussion
이 논문에는 추가 설명과 appendix의 자료가 많았다. 이 중 중요한 부분만 설명하도록 한다.
Self-training에서 Noise에 대해
위에서 말 했듯이 soft pseudo labels를 사용한다. 따라서 student 모델은 teacher 모델에 거의 같은 결과를 내도록 학습되어진다. 그렇다면, 어째서 student 모델이 teacher 모델을 뛰어넘을 수 있을까?
student 모델이 unlabeled images에 대해 학습 할 때 augmentation, stochastic depth 그리고 dropout을 적용하지 않고, labeled images에 대해 학습할 때에만 적용을 하였다. 이렇게 하면 unlabeled images에 noise의 영향을 labeled images의 overfitting 막는 영향으로 부터 분리할 수 있다. 즉 unlabeled images에 noise를 주었을 때 혹은 주지 않았을 때를 중점적으로 비교하기 위해서 세팅을 하였다. 또한 pseudo labels 생성할 때의 teacher 모델에도 noise 관련 비교를 해보았다.
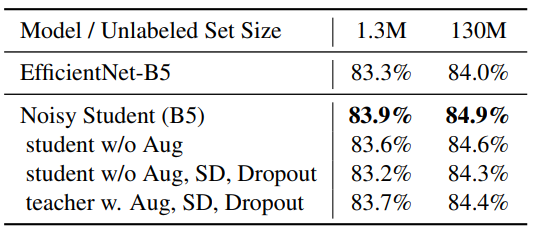
위 표를 보면 세 가지 noise가 성능을 아주 잘 높이고 있는 것을 알 수 있다. 노이즈를 적용한 Noisy Student (B5)와 student w/o Aug 모두 teacher(EfficientNet-B5)에 보다 높은 성능을 기록하였다. 반면에 noise를 제거한 student w/o Aug, SD, Dropout은 teacher에 비해 떨어진 성능을 기록하였다. 또한 선생으로써 pseudo labels을 생성할 때 노이즈를 집어 넣으면 student 때 보다 낮은 성능을 보인다고 하는데 이는 매우 지당한 결론이다.
이 실험의 결론으로는 noise를 student 모델 학습 할때 사용하는 것은 pseudo labeled images에 대해 overfitting을 방지하는 결과를 낸다.
Iterative Trainng에 대해
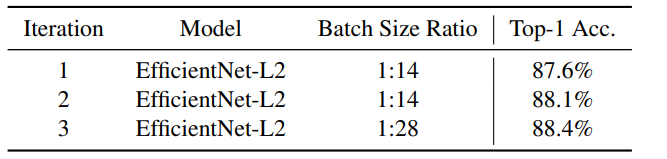
위 표를 보면 첫 번째 iteration 일때는 87.6% 였지만 iteration이 진행 될 수록 높아져서, 마지막 iteration 일 때 88.4%를 달성한다.
Teacher Model의 크기
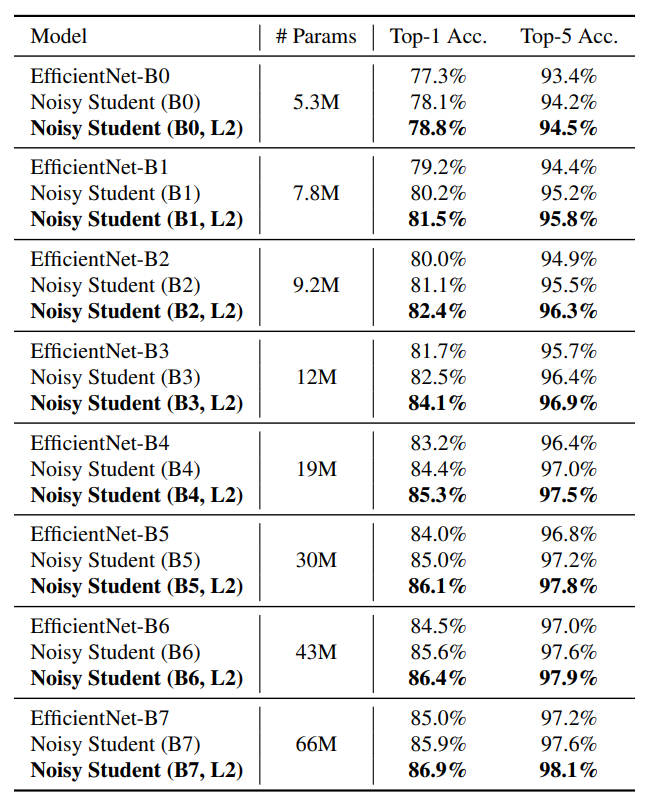
Teacher 모델을 EfficientNet-B0 부터 EfficientNet-B7로 바꾸면서 실험을 해본 결과, Teacher가 크면 클 수록 좋은 성능을 기록하였다.
Student Model의 크기
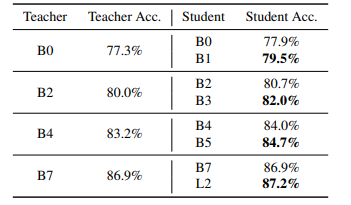
위 표를 보면 teacher model과 같은 size 이거나 조금 더 큰 size의 student model을 비교하였다. 모든 실험이 일관적이게, 같은 teacher이면 더 큰 student가 좋은 성능을 기록하였다. 따라서 student model의 크기가 성능에 있어 매우 중요하다.
hard pseudo-label vs soft pseudo-label
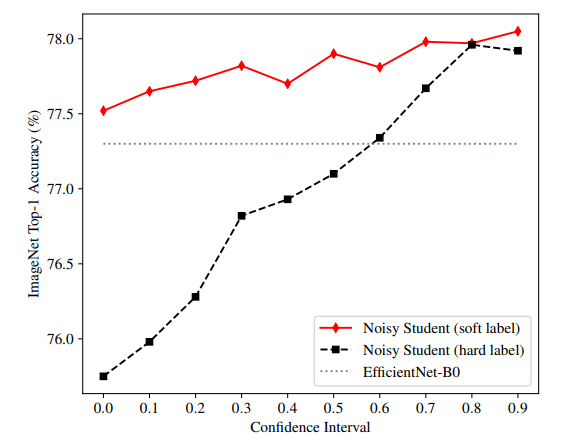
이 논문은 ImageNet의 성능을 높이기 위해 out-of-domain unlabeled data를 사용하였다. 이때 teacher의 confidence는 매우 좋은 지침서가 된다고 한다. 위 그래프에서 x 축은 confidence scores([p, p+0.1])에 속한 이미지를 뜻한다. confidence score가 클 수록 in-domain images, 작을 수록 out-of-domain images라 생각하면 된다.
실험 결과: high-confidence images(in-domain unlabeled images)인 경우 soft pseudo labels과 hard pseudo labels 모두 좋은 성과를 냈다. 하지만 out-of-domain unlabeled images인 경우 soft pseudo labels은 여전히 꽤 좋은 성능을 냈지만 hard pseudo labels은 전혀 성과를 내지 못하였다. 단 teacher 모델이 더 큰 경우에는 hard pseudo labels도 꽤 좋은 성과를 냈기 때문에 상황에 맞춰 쓰면 될 것 이라고 한다.
unlabeled batch size와 labeled batch size의 ratio
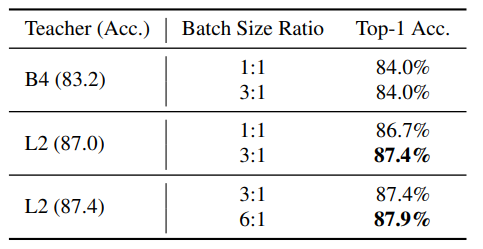
130M개의 unlabeled images와 1.3M개의 labeled images를 사용하였기 때문에 batch size를 다르게 두었다. 저자는 unlabeled batch size를 좀 크게 두어 unlabeled data에 더 잘 학습되도록 하고 싶어서 비율을 차이나게 두었다고 한다.
위 표를 보면 모델의 크기가 클 수록 batch size ratio를 크게 줘야 성능 개선이 이루어진다고 한다.
Reference
- https://blog.lunit.io/2018/03/22/distilling-the-knowledge-in-a-neural-network-nips-2014-workshop/
- https://towardsdatascience.com/review-stochastic-depth-image-classification-a4e225807f4a
- ImageNet-P, ImageNet-C