| ICCV 2019에 발표된 논문이며, Official Code는 PyTorch로 구현되어있다. (Arxiv | Code) |
Task: instance segmentation
Image Segmentation은 이미지를 픽셀 단위의 다양한 segments로 분할하는 task이다. 쉽게 말하자면, 이미지의 모든 픽셀에 라벨을 할당하는 task이다.
Segmentation에는 두 가지 세부문제가 있다. 동일한 클래스에 해당하는 픽셀을 같은 색으로 칠하는 Semantic Segmentation. 동일한 클래스여도 다른 사물의 픽셀이면 다른 색으로 칠하는 Instance Segmentation. 아래 그림을 보면 확연한 차이를 알 수 있다.

이 포스팅에서 소개하려는 논문 YOLACT는 instance segmentation 문제를 real-time으로 푸는 모델이다.
Introduction
Boxes are stupid anyway though, I’m probably a true believer in masks except I can’t get YOLO to learn them - Joseph Redmon, YOLOv3
Instance segmentation 문제를 real-time으로 해결할 수 없을까? 라는 의문으로 시작이 된다. 여태까지의 instance segmentation 모델은 잘 만들어진 object detection에 병렬적으로 모델을 추가하여 (e.g., mask R-CNN(Faster R-CNN), FCIS(R-FCN) 발전하였다. instance segmentation은 매우 어려운 task이여서, object detection의 SSD 그리고 YOLO 모델과 같이 one-stage로 모델을 짜기 힘들기 때문이다. 위의 two-stage 모델은 mask를 생성하기 위해 feature localization에 많은 신경을 썼다 (e.g., RoI align). 하지만 feature localization 후 mask를 예측하는 모델은 순차적으로 이루어질 수 밖에 없고, 스피드를 올릴 수(accelerate)가 없어진다. FCIS는 이를 병렬적으로 수행하였지만 과도한 post-processing 때문에 real-time 과는 거리가 있다.
YOLACT는 localization 단계를 생략한다.
대신에 두 가지 task를 병렬적으로 해결한다.
- 전체 이미지에 대한 prototype mask dictionary 생성
- instance 마다의 linear combination coefficients 예측
각 instance 마다 예측된 coefficients를 이용하여 prototype mask를 linear하게 합친다. 그 후, 예측된 bounding box로 crop한다. 자세한 내용은 Method 부분에서 설명하겠다.
저자는 위 두 task를 이용하면, 네트워크 스스로 (시각적, 공간적, 의미적으로) 비슷한 instance를 다르게 나타내는 instance mask가 잘 localize 될 수 있도록 학습 되어진다고 하였다.
Method
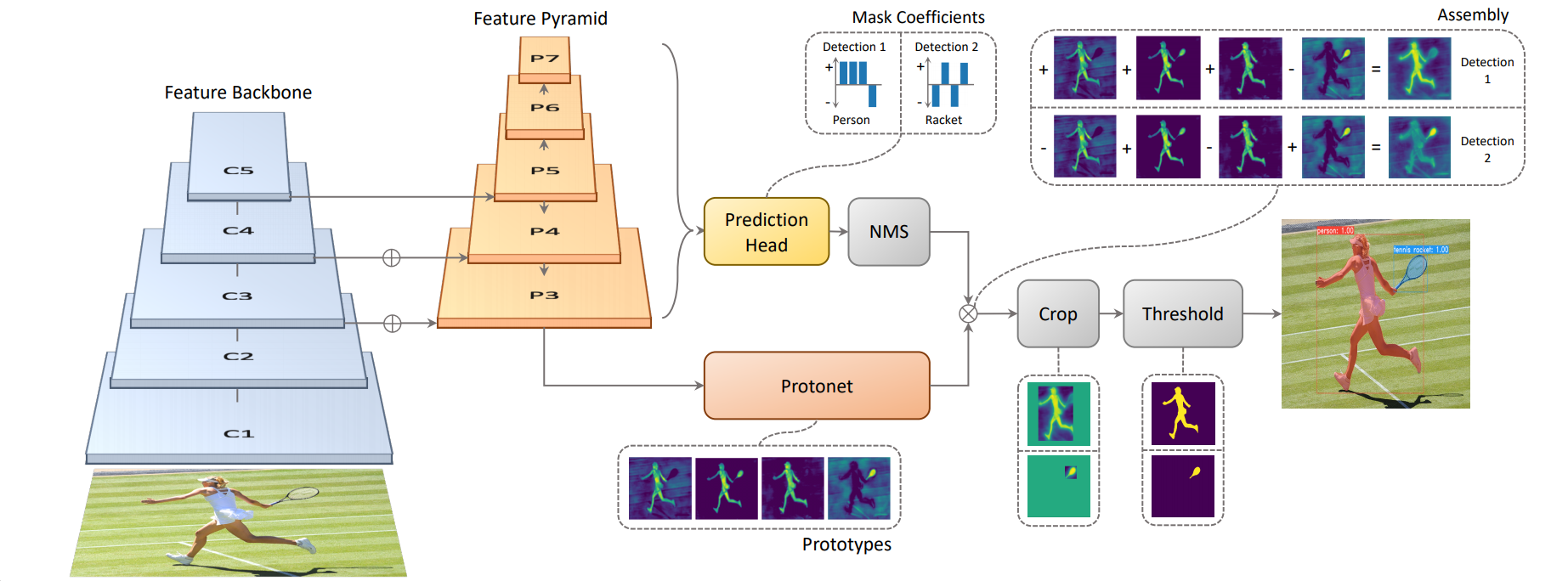
기본 모델은 one-stage object detection 모델인 RetinaNet을 수정하여 사용하였다. 이 one-stage 모델에 feature localization step 없이 mask branch를 추가하기 위해서 instance segmentation task를 두 가지의 간단한 task로 병렬 처리 한다. 위 그림을 보면 Protonet과 Prediction Head로 각각 병렬 처리 되는 것을 알 수 있다.
- FCN을 사용하여 instance에 의존하지 않은 image 크기의 prototype masks 생성하는 task
- prototype 공간에서 instance의 정보를 가진 mask coefficients를 예측하기 위한 object detection task
두 task의 결과물을 linear하게 합쳐서(combine), NMS를 통해 살아남은 instance의 mask를 생성한다.
저자는 masks는 공간적으로 일관성(spatially coherent)이 있기 때문에 위 방식을 선택했다고 한다. semantic한 결과를 얻을 수 있는 fc layer을 통해 mask coefficients를 예측하고, spatially coherent에 탁월한 conv layer을 통해 prototype masks를 생성하였다. 또한 두 결과물을 합칠때 생기는 계산량은 단순한 매트릭스 곱셈이기 때문에 빠르다.
Prototype Generation
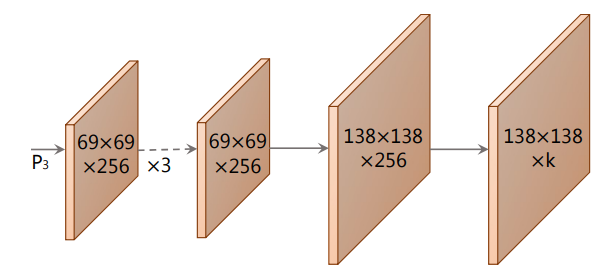
prototype masks를 생성하기 위해 FCN을 사용하였고, 최종 layer은 k 채널을 가지도록 하였다. 이로써 총 k개의 prototype masks를 생성한다.
P3인 경우 deep한 backbone의 featuremap이고, upsample을 하였기 때문에 조그마한 물체에도 좋은 성능을 내는 고 사양 masks를 얻을 수 있다. 마지막으로 ReLU activation function을 사용하여 background를 확실히 구분하였다.
Mask Coefficients
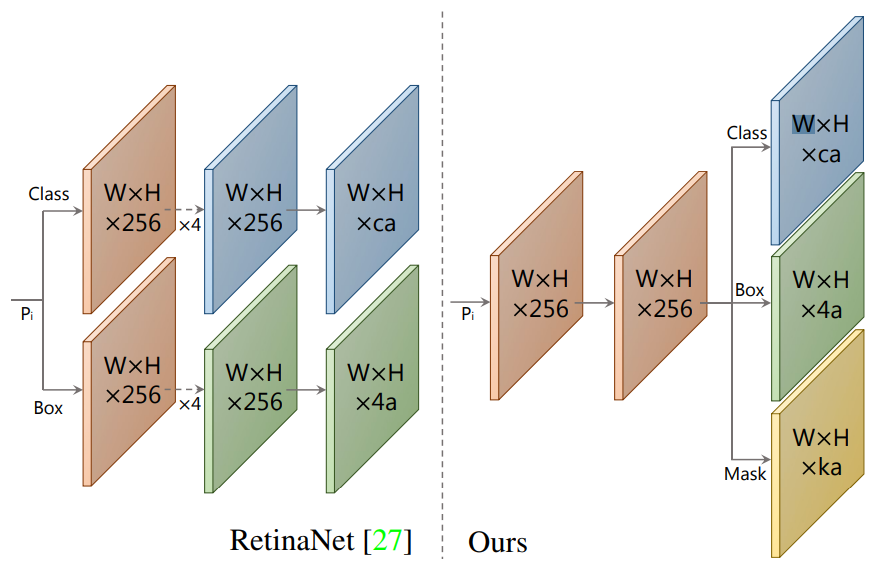
기존 anchor box를 이용하여 object detect하는 모델들은 두 가지를 예측하였다.
- c class confidences
- x, y, w, h의 4 bounding box regressors
이 논문에서는
- k mask coefficients
를 추가로 예측하여 각 prototype에 해당하는 정보를 가지고있다. 결국에는 한 anchor 당 4 + c + k 개의 값을 예측한다.
Mask Assembly
prototype masks에 mask coefficient를 계수로 사용해서 linear combination 한다.
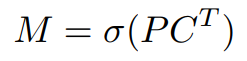
위 수식에서, P는 prototype masks로 h x w x k 의 shape을 가지고 있다. C는 NMS(Fast NMS)와 score thresholding에서 살아남은 n개의 instance의 mask coefficients로 n x k 의 shape을 가지고 있다. 두 매트릭스를 matrix multiplication 후 sigmoid를 사용하면 최종 mask가 나온다.
Loss
classification loss와 box regression loss는 SSD와 같은 방식으로 계산이 된다. 그리고 mask loss는 ground truth와 pixel-wise binary cross entropy(BCE)를 이용하여 계산이된다. 각각 loss에는 weight를 주었는데 classification loss, box regression loss, 그리고 mask loss 각각 1, 1.5, 그리고 6.125를 주었다. 즉 세 loss 중 mask loss에 많은 가중치를 주었다.
최종 mask에서, evaluation 할 때에는 예측한 bounding box를 이용하여 crop한다. 반면에 training 일 때는 작은 object를 잘 보존하기 위해 ground truth bounding box를 이용하여 crop한다. 그리고 mask loss에 ground truth bounding box를 나누어 계산한다.
About Prototype
Mask R-CNN 이나 FCIS인 경우 translation variance 하도록 신경을 많이 썼다. 저자는 crop 단계를 통해 이를 해결하였다고 한다. 하지만 crop 단계를 빼도 중간 크기 이상의 물체에는 translation variance 하다. 이를 통해 본 방법(YOLACT)이 다양한 prototype을 통해 instance의 위치를 잘 학습 할 수 있다고 주장한다.

이미지의 특정 부분을 activate 하기 위해 다양한 prototype을 사용하였다. 위 그림의 첫번째, 두번째, 그리고 세번째 prototype을 보면 각각 한 부분에 위치하는 물체만을 활성화 시키는 것을 알 수 있다. 이 세가지 prototype을 합치면, overlapping 되어있어도 다른 instance를 잘 구분 할 수 있다. 추가로 학습되어진 mask coefficient를 이용하여 이미지에 알맞은 maks를 생성하도록 적절하게 prototype을 압축시킬 수 있다. 실험을 했을 때 k=32 prototype을 써도 성능은 나빠지지 않았지만, coefficient를 예측하는게 쉬운일이 아니라 효과적이지 않다고 한다.
Experiments

위 그림을 통해 기존 두 방법에 비해 더 깔끔한 mask가 예측 되는 것을 알 수 있다.
MS COCO와 Pascal 2012 SBD 데이터셋을 사용하여 실험하였다. 이번 paper review에서는 MS COCO 데이터로 실험한 결과에 대해서만 작성을 하겠다.
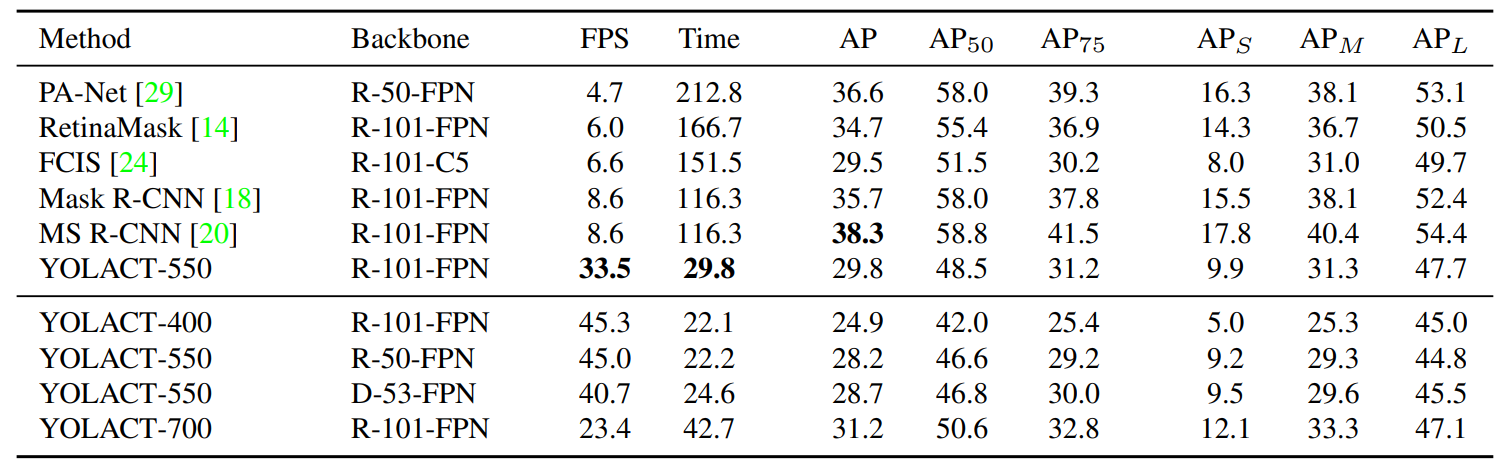
위 표에서 YOLACT-550은 550 x 550 사이즈의 이미지를 인풋으로 가지는 모델이다. 이미지 사이즈가 커질 수록 AP는 높아지고 사이즈가 작아질 수록 fps가 커지는 것을 알 수 있다. 본 논문에서는 YOLACT-550을 기준으로 다른 baseline 모델과 비교를 보였다.
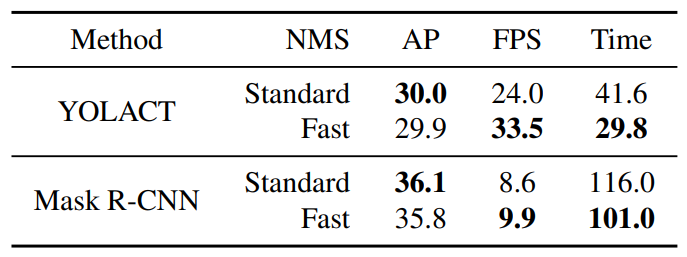
논문에서는 Fast NMS에 대해서도 기술해놓았는데 이 부분은 생략하도록 하겠다. 다만 위 표를 보면 Fast NMS을 썼을 때 일반 NMS보다 성능은 조금 떨어지지만 약 12ms 빠르다고 한다.
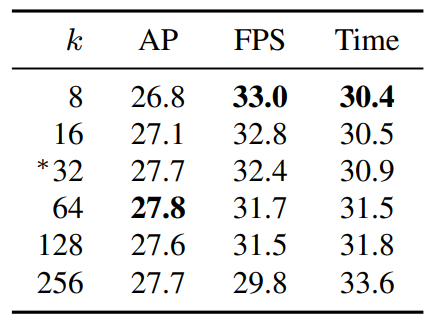
k(prototypes 개수)가 64일 때 AP가 최대를 기록하고, 8일 때 가장 빠르다. 하지만 두 성능을 생각했을 때 본 논문에서는 32를 선택하여 사용하였다고 한다.